

HTMLPad 2016(HTML代码编辑器)
v14.4.0.188 官方版- 软件大小:30.38 MB
- 更新日期:2019-06-24 14:18
- 软件语言:简体中文
- 软件类别:编程工具
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
HTMLPad是集多功能于一身的HTML,CSS,JavaScript和XHTML编辑器,新版本更新了高级搜索和替换功能,在程序中,用户可以在编辑过程中转到任何内容,支持快速搜索、详细搜索、文件搜索、正则表达式、详细结果等;程序还是一款功能强大的JavaScript编辑器,并携带有自动完整的语言工具等,内置拼写检查器,W3 HTML和CSS验证器,CSS检查器,JSLint JavaScript检查器,功能强大的CSS功能,程序还兼容性监视器,前缀器,阴影助手;HTMLPad非常易于学习和使用,它就像一个简单的文本编辑器,提供了许多有用的功能,包括HTML和CSS向导和即时代码片段,浏览器预览等;HTMLPad实际上可以帮助不同用户学习Web编码并减少错误。强大又实用,需要的用户可以下载体验
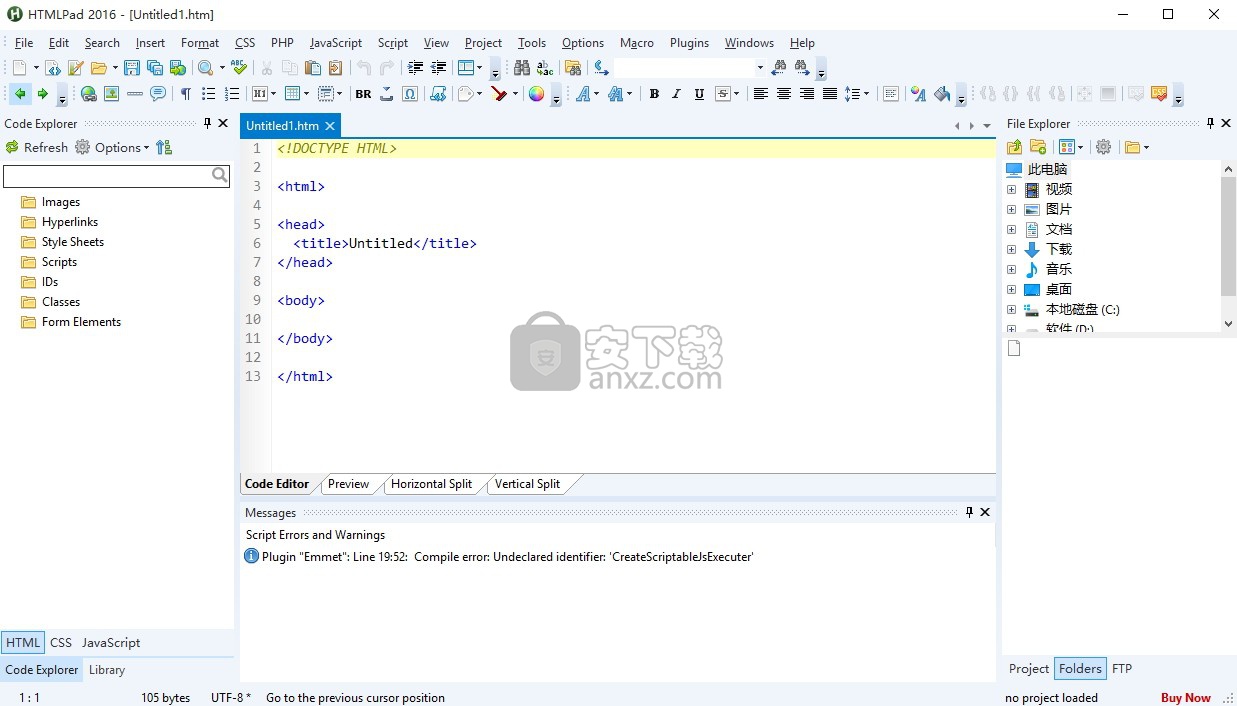
软件功能
改进的文本编辑器
使用异常大的文件提高性能
修复了光标位置的一些怪癖
改进预览
更新了内置的Chrome预览版
改进了Web浏览器检测以进行预览
改进项目管理
在大型项目中更快地完成自动完成
专家现在可以通过todo.ini文件自定义TODO关键字模式
改进了FTP / SFTP / FTPS
更新了SFTP支持并与最新服务器兼容
连接到IPv6地址
修改后保存FTP连接,不仅在应用程序关闭时
各种FTP修复和稳定性改进
改进了HTML和CSS支持
全新,功能强大且最新的HTML格式化程序
新的,功能强大且最新的CSS格式化程序
更新了CSS定义和兼容性信息
更新了HTML Tidy
表单字段标签编辑器现在支持aditional输入类型(例如日期,电子邮件,电话等)
表单字段标记编辑器现在支持新的HTML5属性(例如step,min,max,readonly等)
Anchor标签编辑器现在使用id作为书签链接
改进的CSS语法突出显示
改进了内置的CSS检查器
改进的CSS,LESS,SASS自动完成
更新了CSS前缀
Inspector现在只显示那些仍然需要的前缀属性
现在,collapsibletags.ini中的高级用户可以配置可折叠HTML标记
软件特色
改进的JavaScript支持
改进的JavaScript格式化程序
内置JavaScript最小化器
新的内置JSHint代码检查器和验证器
ES6语法更新(例如,让关键字,模板文字,反向标记字符串)
更灵敏的实时语法检查
更新框架支持
添加了Bootstrap 3和4框架
Laravel框架更新
Wordpress框架更新
插件改进
插件可以轻松执行PHP脚本并获得输出
插件现在可以挂钩到自动完成行为并修改插入的内容
插件现在可以根据用户操作按需执行自动完成
用于解析和创建JSON的新类TScriptableJSON
新的TScriptableJsExecuter用于通过Chromium引擎执行JavaScript文件而不涉及浏览器GUI
TOpenDialog现在通过TOpenDialog.Files属性支持多个文件
安装步骤
1、浏览至此,需要的用户可以点击本网站提供的下载路径下载得到对应的程序安装包
2、通过解压功能将压缩包打开,找到主程序,双击主程序即可进行安装,弹出向导,点击下一步按钮

3、需要完全同意上述协议的所有条款,才能继续安装应用程序,如果没有异议,请点击“同意”按钮;

4、用户可以根据自己的需要点击浏览按钮将应用程序的安装路径进行更改
5、快捷键选择可以根据自己的需要进行选择,也可以选择不创建
6、现在准备安装主程序。点击“安装”按钮开始安装或点击“上一步”按钮重新输入安装信息。
7、等待应用程序安装进度条加载完成即可,需要等待一小会儿
8、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
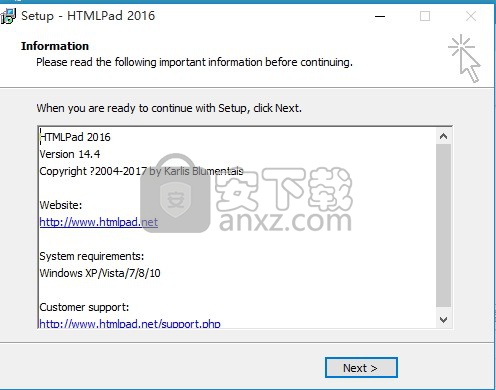
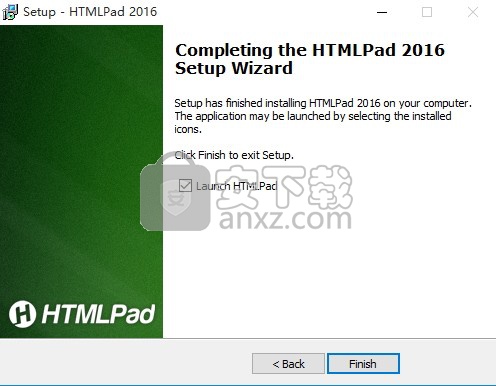
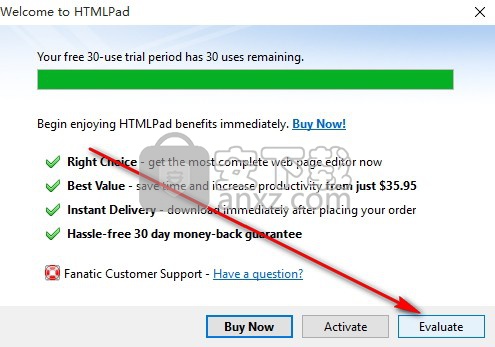
9、双击桌面的快捷键,弹出程序打开设置界面,经过一系列设置即可打开程序

使用说明
HTML的语法受到限制,以避免各种各样的问题。
不直观的错误处理行为
某些无效的语法结构在解析时会导致DOM树非常不直观。
例如,以下标记片段会生成一个DOM,其hr元素是相应元素的早期兄弟table:
可选错误恢复的错误
为了允许用户代理在受控环境中使用而不必实现更奇怪和复杂的错误处理规则,允许用户代理在遇到解析错误时失败。
错误处理行为与流用户代理不兼容的错误
某些错误处理行为(
...例如上述示例的行为) 与流用户代理(在一次传递中处理HTML文件而不存储状态的用户代理)不兼容。为避免此类用户代理的互操作性问题,导致此类行为的任何语法都被视为无效。
可能导致信息强制的错误
当基于XML的用户代理连接到HTML解析器时,HTML文件可能会违反XML强制执行的某些不变量,例如从不包含两个连续连字符的注释。处理此问题可能需要解析器将HTML DOM强制转换为与XML兼容的信息集。大多数需要这种处理的语法结构都被认为是无效的。
导致性能不成比例的错误
某些语法结构可能导致不成比例的糟糕性能。为了阻止使用这种结构,它们通常是不合格的。
例如,以下标记导致性能不佳,因为i必须在每个段落中重建所有未闭合元素,从而导致每个段落中的元素逐渐增加:
由于历史原因,存在语法结构相对脆弱。为了帮助减少意外遇到此类问题的用户数量,他们不合规。
例如,即使省略了结束分号,也会在属性中解析某些命名字符引用。包含一个&符号后跟不形成命名字符引用的字母是安全的,但如果字母更改为形成命名字符引用的字符串,则它们将被解释为该字符。
在此片段中,属性的值为“ ?bill&ted”:
Bill and Ted
但是,在下面的片段中,属性的值实际上是“ ?art©”,而不是预期的“ ?art©”,因为即使没有最后的分号,“ ©”也会被处理为“ ©”,因此被解释为“ ©”:
艺术与复制
为避免此问题,所有命名字符引用都需要以分号结尾,并且不使用分号的命名字符引用的使用将标记为错误。
因此,表达上述案例的正确方法如下:
Bill and Ted <! - &ted没问题,因为它不是命名字符参考 - >
艺术与复制 <! - &必须进行转义,因为&copy 是一个命名字符引用 - >
遗留用户代理中涉及已知互操作性问题的错误
已知某些语法结构在遗留用户代理中引起特别微妙或严重的问题,因此被标记为不符合帮助作者避免它们。
例如,这就是为什么在不带引号的属性中不允许使用“`”(U + 0060)字符。在某些旧版用户代理中, 它有时被视为引用字符。
另一个例子是DOCTYPE,它需要触发无怪癖模式,因为传统用户代理在怪癖模式下的行为通常很大程度上没有记录。
有可能使作者面临安全攻击的错误
存在某些限制纯粹是为了避免已知的安全问题。
例如,使用UTF-7的限制纯粹是为了避免作者使用UTF-7成为已知的跨站点脚本攻击的牺牲品。
作者意图不明确的案例
作者的意图非常不明确的标记通常是不合格的。及早纠正这些错误使以后的维护更容易。
例如,不清楚作者是否打算将以下内容作为 h1标题或 h2标题:
联系方式
可能是错别字的案件
当用户发出简单的拼写错误时,如果可以及早发现错误会很有帮助,因为这可以为作者节省大量的调试时间。因此,该规范通常认为使用与本规范中定义的名称不匹配的元素名称,属性名称等是错误的。
例如,如果作者输入 而不是,则会将其标记为错误,并且作者可以立即更正拼写错误。
可能会影响将来新语法的错误
为了允许将来扩展语言语法,不允许使用某些其他无害的功能。
例如,当前忽略结束标记中的“属性”,但它们无效,以防将来对该语言的更改使用该语法功能而不会与已部署(且有效!)内容冲突。
一些作者发现总是引用所有属性并始终包含所有可选标记的做法很有帮助,更喜欢从这种自定义派生的一致性,而不是通过利用HTML语法的灵活性所提供的简洁性的微小优势。为了帮助这些作者,一致性检查器可以提供其中强制执行这些约定的操作模式。
1.10.3内容模型和属性值的限制
本节不具有规范性。
除了语言的语法之外,此规范还限制了如何指定元素和属性。出于类似原因存在这些限制:
涉及含有可疑语义的内容的错误
为了避免滥用具有已定义含义的元素,定义了内容模型,以限制当这些嵌套具有可疑值时如何嵌套元素。
例如,此规范不允许在section元素内嵌套kbd元素,因为作者极不可能指示应该键入整个部分。
涉及表达语义冲突的错误
同样,为了引起作者对元素使用中的错误的关注,所表达的语义中的明显矛盾也被认为是一致性错误。
例如,在下面的片段中,语义是荒谬的:分隔符不能同时是单元格,单选按钮也不能是进度条。
另一个例子是对ul元素的内容模型的限制,它只允许li元素子元素。根据定义,列表仅包含零个或多个列表项,因此如果ul元素包含除li元素之外的其他 内容,则不清楚其含义。
默认样式可能导致混淆的情况
某些元素具有默认样式或行为,使某些组合可能导致混淆。如果这些具有相同的替代方案而没有这个问题,则不允许混淆的组合。
例如,div元素呈现为块框,元素呈现 span为内联框。将一个块盒放在一个内联盒中是不必要的混淆; 因为要么只是嵌套div元素,要么只嵌套span元素,要么在span元素内嵌套元素div都与将div元素嵌套在元素中的目的相同span,但只有后者涉及内联框中的块框,后一种组合是不允许的。
另一个例子是交互式内容无法嵌套的方式。例如,button元素不能包含 textarea元素。这是因为这种嵌套交互元素的默认行为会使用户高度混淆。它们可以并排放置,而不是嵌套这些元素。
表示可能误解规范的错误
有时,某些东西是不允许的,因为允许它可能会导致作者混淆。
例如,不允许将disabled属性设置为值“ false”,因为尽管表示元素已启用,但实际上意味着该元素已被禁用(对于实现而言,重要的是属性的存在,而不是其值)。
涉及仅为简化语言而施加的限制的错误
一些一致性错误简化了作者需要学习的语言。
例如,area元素的shape属性尽管在实践中接受了两者 circ和circle值作为同义词,但不允许使用该 circ值,以简化教程和其他学习辅助工具。允许两者都没有任何好处,但在教授语言时会引起额外的混乱。
涉及解析器特性的错误
某些元素以某种古怪的方式进行解析(通常是出于历史原因),其内容模型限制旨在避免将作者暴露给这些问题。
例如,form在语法内容中不允许使用元素,因为当解析为HTML时,form元素的开始标记将暗示 p元素的结束标记。因此,以下标记导致两个段落,而不是一个:
欢迎。
名称:
它的解析方式与以下内容完全相同:
欢迎。 名称:
可能导致脚本以难以调试的方式失败的错误
某些错误旨在帮助防止难以调试的脚本问题。
这就是为什么,例如,它具有两个id具有相同值的属性是不一致的。重复的ID导致选择了错误的元素,有时会产生灾难性的影响,其原因很难确定。
浪费创作时间的错误
一些结构是不被允许的,因为从历史上看它们是造成大量浪费创作时间的原因,并且通过鼓励作者避免制作它们,作者可以在未来的努力中节省时间。
例如,script 元素的src属性会导致忽略元素的内容。但是,这并不明显,特别是如果元素的内容看起来是可执行脚本 - 这可能导致作者花费大量时间尝试调试内联脚本而不会意识到它没有执行。为了减少此问题,此规范使得script 在src属性存在时不符合元素中的可执行脚本。这意味着正在验证其文档的作者不太可能浪费时间处理这种错误。
涉及影响作者迁移到XHTML和从XHTML迁移的区域的错误
一些作者喜欢编写可以解释为XML和HTML的文件,但结果相似。虽然由于涉及无数微妙的复杂性(特别是在涉及脚本,样式或任何类型的自动序列化时)而不鼓励这种做法,但是该规范具有一些旨在至少在某种程度上减轻困难的限制。这使得作者在HTML和XHTML之间迁移时更容易将其用作过渡步骤。
例如,有几分围绕复杂的规则lang和xml:lang用于保持两个同步属性。
另一个例子是对xmlnsHTML序列化中属性值的限制,这些限制旨在确保符合文档的元素最终位于相同的名称空间中,无论是作为HTML还是XML处理。
涉及为未来扩展保留的区域的错误
与在将来修订语言时允许新语法的语法限制一样,对元素的内容模型和属性值的一些限制旨在允许HTML词汇表的未来扩展。
例如,target将以“_”(U + 005F)字符开头的属性的值限制 为仅特定的预定义值允许在将来的时间引入新的预定义值,而不会与作者定义的值冲突。
表示误用其他规格的错误
某些限制旨在支持其他规范所做的限制。
例如,要求采用媒体查询的属性仅使用有效的媒体查询,这强化了遵循该规范的一致性规则的重要性。
软件开发人员和内容开发人员提供了万维网上可互操作文本操作的通用参考,建立在由Unicode标准和ISO / IEC 10646共同定义的通用字符集上。使用术语'字符','编码'和'字符串',参考处理模型,字符编码的选择和识别,字符转义和字符串索引。
Unicode安全注意事项 [UTR36]
由于Unicode包含如此大量的字符并且包含了世界上不同的编写系统,因此不正确的使用会使程序或系统暴露于可能的安全攻击。随着越来越多的产品国际化,这一点尤为重要。本文档介绍了程序员,系统分析员,标准开发人员和用户应考虑的一些安全注意事项,并提供了降低问题风险的具体建议。
网页内容无障碍指南(WCAG)2.0 [WCAG]
Web内容可访问性指南(WCAG)2.0涵盖了使Web内容更易于访问的各种建议。遵循这些指南将使更多残疾人可以访问内容,包括失明和视力低下,耳聋和听力丧失,学习障碍,认知限制,运动受限,言语障碍,光敏性以及这些组合。遵循这些指南通常也会使您的Web内容对用户更有用。
多语言标记:HTML兼容的XHTML文档 [POLYGLOT]
使用多语言标记的文档是一个文档,它是一个字节流,当作为HTML处理并作为XML处理时,它会解析为相同的文档树(根元素上的xmlns属性除外)。根据HTML5规范,符合定义良好的约束集的多语言标记被解释为兼容,无论它们是作为HTML还是作为XHTML处理。Polyglot标记使用特定的DOCTYPE,名称空间声明和特定的案例 - 通常是小写但偶尔使用驼峰案例 - 用于元素和属性名称。多语言标记对某些属性值使用小写。进一步的约束包括空元素,命名实体引用以及脚本和样式的使用。
HTML到平台辅助功能API实施指南 [HPAAIG]
这是草案文档,将HTML元素和属性映射到各种平台上的可访问性API角色,状态和属性。它提供了有关派生HTML元素的可访问名称和描述的建议。它还提供了可访问的功能实现示例。
除了语言的语法之外,此规范还限制了如何指定元素和属性。出于类似原因存在这些限制:
涉及含有可疑语义的内容的错误
为了避免滥用具有已定义含义的元素,定义了内容模型,以限制当这些嵌套具有可疑值时如何嵌套元素。
例如,此规范不允许在section元素内嵌套kbd元素,因为作者极不可能指示应该键入整个部分。
涉及表达语义冲突的错误
同样,为了引起作者对元素使用中的错误的关注,所表达的语义中的明显矛盾也被认为是一致性错误。
例如,在下面的片段中,语义是荒谬的:分隔符不能同时是单元格,单选按钮也不能是进度条。
另一个例子是对ul元素的内容模型的限制,它只允许li元素子元素。根据定义,列表仅包含零个或多个列表项,因此如果ul元素包含除li元素之外的其他 内容,则不清楚其含义。
默认样式可能导致混淆的情况
某些元素具有默认样式或行为,使某些组合可能导致混淆。如果这些具有相同的替代方案而没有这个问题,则不允许混淆的组合。
例如,div元素呈现为块框,元素呈现 span为内联框。将一个块盒放在一个内联盒中是不必要的混淆; 因为要么只是嵌套div元素,要么只嵌套span元素,要么在span元素内嵌套元素div都与将div元素嵌套在元素中的目的相同span,但只有后者涉及内联框中的块框,后一种组合是不允许的。
另一个例子是交互式内容无法嵌套的方式。例如,button元素不能包含 textarea元素。这是因为这种嵌套交互元素的默认行为会使用户高度混淆。它们可以并排放置,而不是嵌套这些元素。
表示可能误解规范的错误
有时,某些东西是不允许的,因为允许它可能会导致作者混淆。
例如,不允许将disabled属性设置为值“ false”,因为尽管表示元素已启用,但实际上意味着该元素已被禁用(对于实现而言,重要的是属性的存在,而不是其值)。
涉及仅为简化语言而施加的限制的错误
一些一致性错误简化了作者需要学习的语言。
例如,area元素的shape属性尽管在实践中接受了两者 circ和circle值作为同义词,但不允许使用该 circ值,以简化教程和其他学习辅助工具。允许两者都没有任何好处,但在教授语言时会引起额外的混乱。
涉及解析器特性的错误
某些元素以某种古怪的方式进行解析(通常是出于历史原因),其内容模型限制旨在避免将作者暴露给这些问题。
例如,form在语法内容中不允许使用元素,因为当解析为HTML时,form元素的开始标记将暗示 p元素的结束标记。因此,以下标记导致两个段落,而不是一个:
欢迎。
名称:
它的解析方式与以下内容完全相同:
欢迎。 名称:
可能导致脚本以难以调试的方式失败的错误
某些错误旨在帮助防止难以调试的脚本问题。
这就是为什么,例如,它具有两个id具有相同值的属性是不一致的。重复的ID导致选择了错误的元素,有时会产生灾难性的影响,其原因很难确定。
浪费创作时间的错误
一些结构是不被允许的,因为从历史上看它们是造成大量浪费创作时间的原因,并且通过鼓励作者避免制作它们,作者可以在未来的努力中节省时间。
例如,script 元素的src属性会导致忽略元素的内容。但是,这并不明显,特别是如果元素的内容看起来是可执行脚本 - 这可能导致作者花费大量时间尝试调试内联脚本而不会意识到它没有执行。为了减少此问题,此规范使得script 在src属性存在时不符合元素中的可执行脚本。这意味着正在验证其文档的作者不太可能浪费时间处理这种错误。
涉及影响作者迁移到XHTML和从XHTML迁移的区域的错误
一些作者喜欢编写可以解释为XML和HTML的文件,但结果相似。虽然由于涉及无数微妙的复杂性(特别是在涉及脚本,样式或任何类型的自动序列化时)而不鼓励这种做法,但是该规范具有一些旨在至少在某种程度上减轻困难的限制。这使得作者在HTML和XHTML之间迁移时更容易将其用作过渡步骤。
例如,有几分围绕复杂的规则lang和xml:lang用于保持两个同步属性。
另一个例子是对xmlnsHTML序列化中属性值的限制,这些限制旨在确保符合文档的元素最终位于相同的名称空间中,无论是作为HTML还是XML处理。
涉及为未来扩展保留的区域的错误
与在将来修订语言时允许新语法的语法限制一样,对元素的内容模型和属性值的一些限制旨在允许HTML词汇表的未来扩展。
例如,target将以“_”(U + 005F)字符开头的属性的值限制 为仅特定的预定义值允许在将来的时间引入新的预定义值,而不会与作者定义的值冲突。
表示误用其他规格的错误
某些限制旨在支持其他规范所做的限制。
例如,要求采用媒体查询的属性仅使用有效的媒体查询,这强化了遵循该规范的一致性规则的重要性。
其他小调整和修复
改进:基于关键字的代码折叠
改进:现在,在多个文件中搜索会将更多内容滚动到视图中
改进:在行选择期间意外设置意外断点的可能性最小化
改进:改进的HTML标记关闭,现在支持Blade模板
修复:如果从FTP打开文件,发布到FTP的错误工作不正确
修复:从“项目”窗口创建的FTP连接错误未显示在“FTP”选项卡上
修正:FTP传输进度条在某些情况下
修复:多个Inspector错误,包含值编辑和插入
修复:在语法检查期间CSS选择器出现大写的错误
修复:在某些情况下,未正确插入META编码的错误
修复:从Windows文件资源管理器打开文件时,最大化的应用程序窗口出现在顶部的错误
各种其他修复
人气软件
-

redis desktop manager2020.1中文 32.52 MB
/简体中文 -

s7 200 smart编程软件 187 MB
/简体中文 -

GX Works 2(三菱PLC编程软件) 487 MB
/简体中文 -

CIMCO Edit V8中文 248 MB
/简体中文 -

JetBrains DataGrip 353 MB
/英文 -

Dev C++下载 (TDM-GCC) 83.52 MB
/简体中文 -

TouchWin编辑工具(信捷触摸屏编程软件) 55.69 MB
/简体中文 -
信捷PLC编程工具软件 14.4 MB
/简体中文 -

TLauncher(Minecraft游戏启动器) 16.95 MB
/英文 -

Ardublock中文版(Arduino图形化编程软件) 2.65 MB
/简体中文
 Embarcadero RAD Studio(多功能应用程序开发工具) 12
Embarcadero RAD Studio(多功能应用程序开发工具) 12  猿编程客户端 4.16.0
猿编程客户端 4.16.0  VSCodium(VScode二进制版本) v1.57.1
VSCodium(VScode二进制版本) v1.57.1  aardio(桌面软件快速开发) v35.69.2
aardio(桌面软件快速开发) v35.69.2  一鹤快手(AAuto Studio) v35.69.2
一鹤快手(AAuto Studio) v35.69.2  ILSpy(.Net反编译) v8.0.0.7339 绿色
ILSpy(.Net反编译) v8.0.0.7339 绿色  文本编辑器 Notepad++ v8.1.3 官方中文版
文本编辑器 Notepad++ v8.1.3 官方中文版 






