

PowerGREP(正则表达式应用软件)
v4.6 中文- 软件大小:15.9 MB
- 更新日期:2019-08-30 08:51
- 软件语言:简体中文
- 软件类别:文件管理
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
PowerGREP是一款简单易用的文件搜索编译软件,主要用于文本和二进制文件的高级文件查找器,该应用程能够支持正则表达式,内置文本编辑器,具有预定义操作的库等。要缩小搜索结果范围,可以考虑文件修改日期和大小。它还具有包含预定义操作的库,例如向文件添加页眉和页脚,收集编号列表,删除重复的单词或查找电子邮件地址。另外,还具有一个内置的文本编辑器,使您可以查看撤消历史记录,当然,这些只是此软件应用程序提供的选项的一部分,其具备完善功能,而且界面非常的直观,有需要的用户赶紧下载吧!
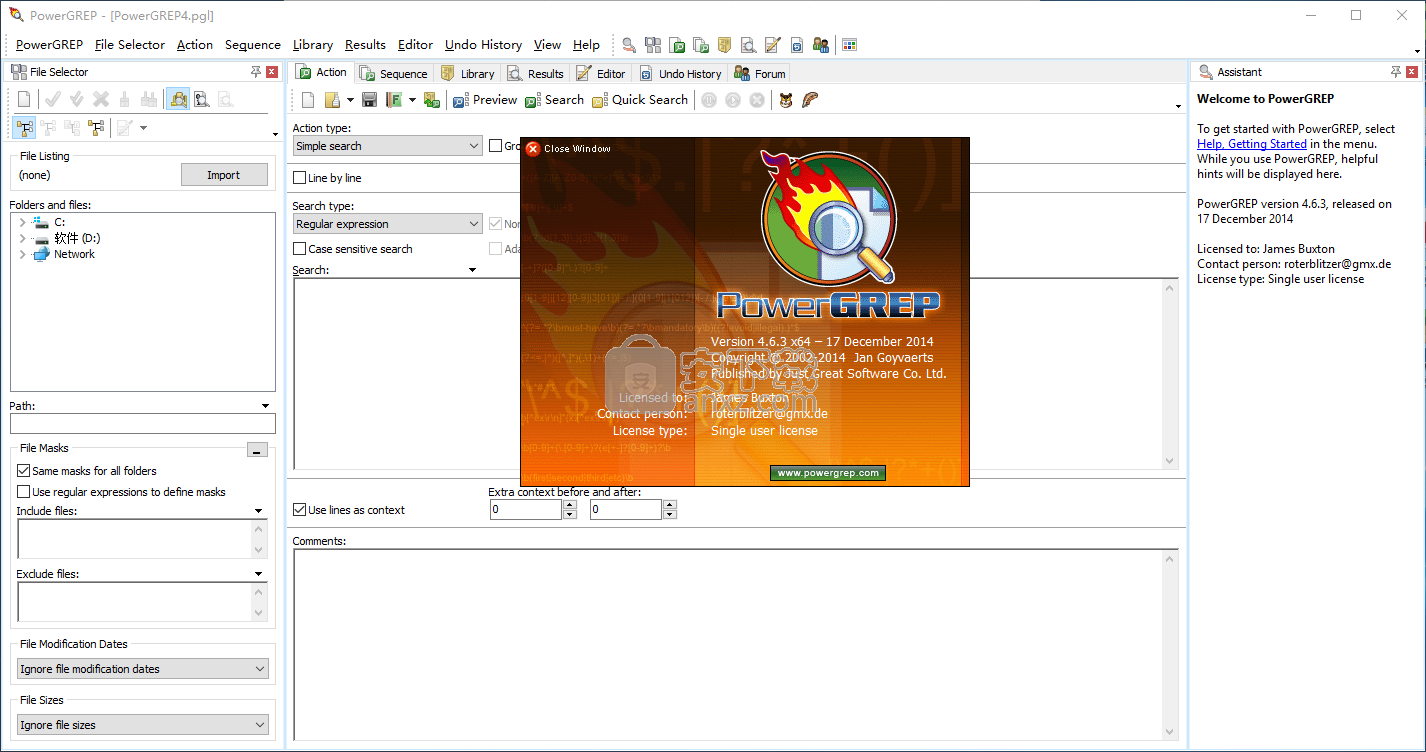
软件功能
PowerGREP是一个功能强大的软件实用程序,旨在通过为您提供正则表达式来帮助您有效地搜索文本和二进制文件。它为经验丰富的用户提供了一系列高级选项和配置参数。
具有高级功能的专业UI
经过快速而简单的设置程序后,您将受到一个专业外观的欢迎,该界面由一个包含多个窗格的清晰结构的大窗口代表。
多种搜索模式和配置设置
PowerGREP允许您执行简单搜索,收集数据,获取特定位置中所有文件的列表,浏览文件名,查找和替换或删除关键字,以及合并或拆分文件。
每种操作类型都有自己的一组过滤器和其他设置。例如,在执行简单搜索时,您可以要求工具将相同的匹配组合成组,并在保留空行的同时分别浏览文件中的每行文本。
通过应用过滤器缩小搜索结果范围
此外,您可以选择正则表达式,文本文本,列表或文字文本,分隔文本文本,自由间距正则表达式,正则表达式列表,二进制数据等之间的搜索类型。
它对机器的整体性能有影响,因为它使用了低CPU和RAM。考虑到其广泛的专家选择,PowerGREP应该满足那些寻找多功能和专业文件搜索器的人的要求。
软件特色
首选项,文件格式:IFilter文件掩码现在包含* .od [bcfgimpst],这样如果安装了OpenOffice或LibreOffice,PowerGREP将使用OpenOffice或LibreOffice IFilter for OpenDocument Format文件。
操作:将搜索类型从列表更改为单个项目,然后返回而不编辑项目将恢复上一个列表,从而允许意外更改搜索类型以撤消。
操作:将搜索类型从列表更改为单个项目现在可以保留列表中选定的项目(如果它不是空白),而不是保留列表中第一个启用的非空白项目。
HTML元标记检测现在忽略指定不可能的字符集的元标记。
重命名文件:检查替换文本生成的路径是否在语法上有效,如果不是,则显示错误,而不是尝试将文件重命名为明显无效的路径。
存档格式:现在支持使用LZMA而不是GZIP压缩的RPM文件。
何时使用:
在PC或网络上的任何位置查找文件和信息
全面编辑,维护或转换大量数据文件或文档
从日志文件或存档中收集信息和统计信息
独特能力:
顺序或同时应用任意数量的正则表达式搜索项
搜索特定文件部分
搜索前将文件拆分为记录
要收集的后处理替换文本或文本
使用永久撤消历史记录保持安全
审核或法医分析后不要留下痕迹
多功能一体工具:
比大多数Windows grep工具更易于使用
浏览PC和网络上的文件,文件夹,存档
内置全功能文本和十六进制编辑器
广泛兼容:
Perl,Java和.NET兼容的正则表达式
广泛的文本编码支持:Windows和DOS代码页,Unicode,ISO-8859,ECBDIC,KOI8等。
搜索MS Word和PDF文档
搜索Excel,Lotus 1-2-3和Quattro Pro电子表格
搜索OpenOffice文档,电子表格等。
搜索并移动ZIP档案中的文件
安装方法
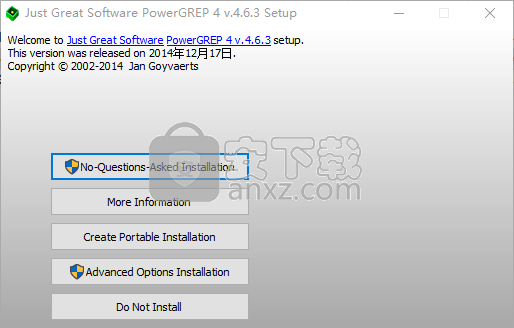
1、下载并解压软件,双击安装程序弹出如下的安装界面,用户可以选择,提供了以下的安装选项,普通用户选择【No-Questions-Asked Installation(无问题安装)】即可。
无问题安装
更多信息
创建便携式安装
高级选项安装
不要安装
2、随即进入如下的安装许可协议,点击【Yes,I do】按钮。
3、正在安装PowerGREP,等待安装完成。
4、弹出如下的PowerGREP安装成功的提示,点击【thank】完成。
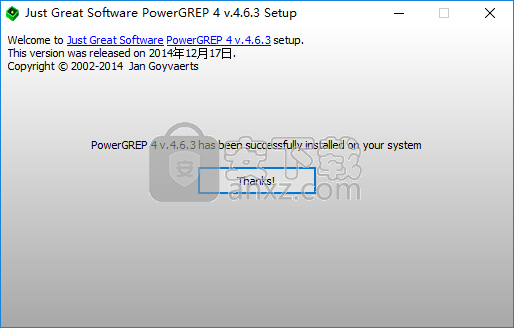
5、运行PowerGREP,可以看到显示为已注册的版本。
使用说明
替换文件名和内容
您可以使用“重命名文件”操作类型搜索和替换文件名。您可以使用“搜索和替换”操作类型搜索和替换文件内容。 PowerGREP没有同时执行这两种操作的操作类型。幸运的是,我们可以使用Sequence面板作为一个操作执行两个操作。
假设您有一组需要每年更新的文件。需要更新的文件的文件名中包含年份。您必须使用文件名中的新年创建这些文件的副本。您还必须替换这些文件内容中的年份。
在文件选择器中选择要更新的文件。
从一个新的行动开始。
将操作类型设置为“重命名文件”。
如果包含文件的文件夹中也包含年份编号,并且您要为新年创建新文件夹,请将“要重命名的内容”设置为“完整路径”。
在“搜索”框中,输入旧年(例如2010年)。
在“替换”框中,输入新年(例如2011年)。
将“目标文件创建”设置为“复制文件”。
根据需要设置备份文件选项。
单击“序列”面板上的“新建步骤”按钮,将“操作”面板的内容添加为序列中的第一步。
在“操作”面板上,将操作类型更改为“搜索和替换”。
将“目标文件创建”设置为“修改原始文件”。在这种情况下,原始文件将是序列中第一步复制的文件。
单击“序列”面板上的“新建步骤”按钮,将“操作”面板的内容添加为序列中的第二步。
在“序列”面板上仍然选择第二步后,在“文件选择”下拉列表中选择“其他步骤中的目标文件”。
在“步骤”下拉列表中选择第1步。第二步现在配置为处理第一步创建的目标文件。
单击“序列”面板上的“执行”按钮以执行这两个步骤。第一步复制文件,将路径中的2010更改为2011.完成后,第二步搜索复制文件的内容,将2010替换为2011。
此序列在PowerGREP.pgl库中可用作“替换文件名和内容”。
在正则表达式中添加注释
如果您已完成整个教程,我想您会同意正则表达式很快就会变得相当神秘。因此,许多现代正则表达式风格允许您在正则表达式中插入注释。语法是(?#comment)其中“comment”可以是您想要的任何内容,只要它不包含结束圆括号即可。正则表达式引擎忽略了(?#到第一个关闭圆括号之后的所有内容)。
例如。我可以通过将其写成(?#year)(19 | 20)\ d \ d [ - /.](?#month)(0[1-9]|1[012]来澄清正则表达式以匹配有效日期)[ - /.](?#day)(0[1-9]|[12][0-9]|3[01])。现在很明显,这个正则表达式与yyyy-mm-dd格式的日期匹配。某些软件(如RegexBuddy,EditPad Pro和PowerGREP)可以在编写时将语法着色应用于正则表达式。这使评论真正脱颖而出,在正确的位置启用正确的评论,使复杂的正则表达式更容易理解。
JGsoft引擎,.NET,Perl,PCRE,Python和Ruby支持正则表达式注释。
要使正则表达式更具可读性,可以打开自由间距模式。支持注释的所有口味也支持自由间隔模式。此外,Java支持自由间隔模式,即使它不支持(?#)样式注释。

自由间隔正则表达式
JGsoft引擎,.NET,Java,Perl,PCRE,Python,Ruby和XPath支持称为自由间隔模式的正则表达式语法的变体。您可以使用(?x)模式修改器打开此模式,或者打开应用程序中的相应选项或将其传递给编程语言中的正则表达式构造函数。
在自由间隔模式下,忽略正则表达式标记之间的空格。空格包括空格,制表符和换行符。请注意,只会忽略标记之间的空格。例如。 a b c与自由间隔模式下的abc相同,但\ d和\ d不相同。前者匹配d,后者匹配数字。 \ d是由反斜杠和“d”组成的单个正则表达式标记。用空格分解标记会为您提供一个转义空间(与空格匹配)和一个文字“d”。
同样,分组修饰符也不能分解。 (?>原子)与(?> ato mic)和(?> ato mic)相同。它们都匹配相同的原子组。它们与(?>原子)不一样。实际上,后者会导致语法错误。 ?>分组修饰符是正则表达式语法中的单个元素,必须保持在一起。对于所有此类构造都是如此,包括外观,命名组等。
字符类也被视为单个标记。 [abc]与[a b c]不同。前者匹配三个字母中的一个,而后者匹配这三个字母或空格。换句话说:自由间隔模式在字符类中没有任何影响。字符类中的空格和换行符将包含在字符类中。
这意味着在自由间隔模式下,您可以使用\或[]匹配单个空格。使用您认为更具可读性的任何一个。
但是,Java不会将字符类视为自由间隔模式下的单个标记。 Java确实忽略了字符类中的空格和注释。所以在Java的自由间隔模式中,[abc]与[a b c]相同,而\是匹配空间的唯一方法。然而。即使在自由间距模式下,否定插入符号必须在开启括号后立即出现。 [^ a b c]匹配四个字符^,a,b或c中的任何一个,就像[abc ^]一样。在正确的位置使用否定插入符号,[^ a b c]匹配任何不是a,b或c的字符。
Free-Spacing模式中的注释
自由间隔模式的另一个特征是#字符开始发表评论。评论一直持续到行尾。从#到下一个换行符的所有内容都将被忽略。
XPath flavor不支持正则表达式中的注释。 #始终被视为文字字符。
总而言之,我可以通过将其写在多行中来澄清正则表达式以匹配有效日期:
#以yyyy-mm-dd格式匹配20或21世纪的日期
(19 | 20)\ d \ d#year(第1组)
[- /。] # 分隔器
(0 [1-9] | 1 [012])#个月(第2组)
[- /。] # 分隔器
(0 [1-9] | [12] [0-9] | 3 [01])#day(第3组)

Delphi正则表达式类
Delphi XE是Delphi的第一个版本,它内置了对正则表达式的支持。在大多数情况下,您将使用RegularExpressions单位。该单元定义了一组模拟.NET框架中正则表达式类的记录。就像在.NET中一样,它们允许您在一行代码中使用正则表达式而无需显式内存管理。
在内部,RegularExpressions单元使用定义TPerlRegEx类的RegularExpressionsCore单元。 TPerlRegEx是开源PCRE库的包装器。因此,RegularExpressions和RegularExprssionsCore单元都使用PCRE正则表达式。
在性能至关重要的情况下,您可能希望直接使用TPerlRegEx。 PCRE库基于UTF-8,而Delphi VCL使用UTF-16(UnicodeString)。 TPerlRegEx也基于UTF-8,使您可以完全控制UTF-16和UTF-8之间的转换。如果您自己的代码也使用UTF8String,则可以避免转换。 RegularExpressions单元使用UnicodeString,就像VCL的其余部分一样,并自动处理UTF-16到UTF-8的转换。
对于用Delphi XE编写的新代码,您绝对应该使用属于Delphi的RegularExpressions单元,而不是可用的许多第三方单元之一。如果您正在处理UTF-8数据,请使用RegularExpressionsCore单元以避免不必要的UTF-8到UTF-16到UTF-8的转换。
重复捕获组与捕获重复组
当创建需要捕获组来捕获部分匹配文本的正则表达式时,常见的错误是重复捕获组而不是捕获重复的组。不同之处在于重复捕获组将仅捕获最后一次迭代,而捕获另一个重复捕获组的组将捕获所有迭代。一个例子可以说明这一点。
假设你想匹配像!abc这样的标签!或者!123!只有这两个是可能的,你想捕获abc或123来找出你得到的标签。这很容易:!(abc | 123)!会做的。
现在让我们说标签可以包含多个abc和123的序列,比如!abc123!或者!123abcabc!快速简便的解决方案是!(abc | 123)+!。这个正则表达式确实匹配这些标签。但是,它不再符合我们将标签的标签捕获到捕获组中的要求。当这个正则表达式匹配!abc123!时,捕获组只存储123.当它匹配!123abcabc!时,它只存储abc。
如果我们看看正则表达式引擎如何应用,这很容易理解!(abc | 123)+!来!abc123!首先,!火柴 !。然后引擎进入捕获组。它注意到当引擎到达主题字符串中第一个和第二个字符之间的位置时,输入了捕获组#1。组中的第一个标记是abc,它与abc匹配。找到匹配,因此不尝试第二种替代方案。 (引擎确实存储了一个回溯位置,但在本例中不会使用它。)引擎现在离开了捕获组。它注意到当引擎到达字符串中第4个和第5个字符之间的位置时,会退出捕获组#1。
退出该组后,引擎注意到加号。加分是贪婪的,所以小组再次尝试。引擎再次进入组,并注意到在组合字符串中的第4个和第5个字符之间输入了捕获组#1。它还注意到,由于加号不是占有性,它可能会被回溯。也就是说,如果该组第二次无法匹配,那很好。在此回溯记录中,正则表达式引擎还在组的上一次迭代期间保存组的入口和出口位置。
abc无法匹配123,但123成功。该小组再次退出。存储字符7和8之间的退出位置。
加号允许另一次迭代,因此引擎再次尝试。存储回溯信息,并保存组的新入口位置。但是现在,abc和123都无法匹配!该组失败,引擎回溯。在回溯时,引擎恢复组的捕获位置。即,该组在字符4和5之间输入,并且存在于字符7和8之间。
引擎继续!,匹配!找到整体匹配。整体匹配跨越整个主题字符串。捕获组将字符5,6和7或123放空。当找到匹配时,将丢弃回溯信息,因此在该组具有与abc匹配的先前迭代的事实之后无法判断。 (唯一的例外是.NET正则表达式引擎,它会在匹配尝试后保留用于捕获组的回溯信息。)
在这个例子中捕获abc123的解决方案现在应该是显而易见的:正则表达式引擎应该只进入和离开组一次。这意味着加号应该在捕获组内而不是在外部。由于我们确实需要对两个备选方案进行分组,因此我们需要在重复的组周围放置第二个捕获组:!((abc | 123)+)!.当这个正则表达式匹配!abc123!时,捕获组#1将存储abc123,组#2将存储123.由于我们对内组的匹配不感兴趣,我们可以通过使内组不捕获来优化此正则表达式:!((?:abc | 123)+)!
更新日志
改进:
文件格式:IFilter转换现在在一个单独的进程中完成,因此第三方IFilter DLL中的崩溃或挂起不会导致PowerGREP失效; 它还允许同时转换多个文件。
文件格式:XLS和XLSX文本转换不再添加尾随空白行和列。
帮助:更好地解决IE 9中使用HTML帮助导致64位应用程序崩溃的错误,允许PowerGREP显示正确的帮助主题,而不是帮助文件的第一页。
首选项|常规:在Windows资源管理器中右键单击文件夹中添加PowerGREP现在还将其添加到Windows资源管理器中文件夹背景(文件夹视图中的空白区域)的右键菜单中。
RegexBuddy:PowerGREP的便携式安装现在可以与RegexBuddy 4的便携式安装集成。
RegexBuddy:当向RegexBuddy发送正则表达式列表时,让RegexBuddy激活在PowerGREP中选择的那个而不是第一个。需要RegexBuddy 4.0.0或更高版本。
Bug修复:
操作:当需要复制或移动压缩文档时,文件名搜索失败并出现访问冲突。
存档:现在可以正确处理创建或更新存档时出现的错误。
文件格式:如果文件位于存档中并且您的首选项设置为使文件只需要IFilter转换(如果它是二进制或纯文本),则IFilter转换崩溃; 如果文件不在存档中,或者您对该类型文件的首选项设置为始终使用IFilter转换,则IFilter转换可正常工作。
文件格式:某些XLS和XLSX文件导致转换器进程崩溃。
如果您在成功连接到论坛后更改了代理设置,则论坛将继续使用旧的代理设置,直到您重新启动PowerGREP。
库:双击列表中最后一项下面的空白区域会导致无害的访问冲突错误。
人气软件
-

PDF去水印工具(PDF Watermark Remover) 9.69 MB
/简体中文 -

万能文件打开器(FileViewPro) 58.1 MB
/简体中文 -

Beyond Compare 3中文 33.48 MB
/简体中文 -

目录文件清单生成工具 Excel清单 绿色版 5.00 MB
/简体中文 -

空文件夹清理工具(EmptyFolderNuker) 0.16 MB
/简体中文 -

LDAP Admin(LDAP管理工具) 1.84 MB
/简体中文 -
ePDF 5.35 MB
/简体中文 -

picture manager 2013单独安装包 19.65 MB
/简体中文 -

project reader中文版 8.96 MB
/简体中文 -

笔记本wifi万能钥匙电脑版 10.46 MB
/简体中文
 华为云空间 v15.3.0.300
华为云空间 v15.3.0.300  联想Filez 9.4.3.0
联想Filez 9.4.3.0  文件管理器 XYplorer v24.70.0000
文件管理器 XYplorer v24.70.0000  FreeFileSync v12.2 绿色
FreeFileSync v12.2 绿色  UltraCompare Pro 18中文 32/64位 附注册机
UltraCompare Pro 18中文 32/64位 附注册机  Deltawalker(文件比对工具) v2.3.2 免费版
Deltawalker(文件比对工具) v2.3.2 免费版 












