

intel parallel studio xe 2018 update 3
附安装教程- 软件大小:3533 MB
- 更新日期:2020-03-24 13:26
- 软件语言:简体中文
- 软件类别:编程工具
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
intel parallel studio xe 2018 update 3是一款非常实用的数据分析和统计套件,新版本扩展了对云的支持,借助该程序在AWS的Elastic Fabric Adapter(EFA)的基础支持中实现云中的HPC作业,以实现低延迟和高带宽,并支持Amazon Linux 2 OS;此程序还扩展了对Fortran 2018和完整C ++ 17的标准支持;新版本在程序编程库中增加了对AWS EFA(弹性结构适配器)的支持;同时还添加了透明的奇点(3.0+)容器支持,而无需外部Mpirun或intel MPI库中的进程管理器;因特尔数学内核库函数LAPACK,ScaLAPACK和FFT通过指令集和线程优化来提高性能;GNU调试器已更新至8.2.1版,并具有函数入口点,断点等更多功能;英特尔VTune放大器添加了新的硬件事件支持和增强的内存分析功能,以设计和优化对英特尔傲腾DC持久性内存和第二代英特尔至强可扩展处理器的支持;系统改进了用户界面摘要窗格的用户界面,添加了屋顶线指导作为预览功能,并增加了对AVX-512矢量神经网络指令的分析支持,改进了Inspector内存检查器分析,以减少误报诊断;MPI库通过添加应用程序运行时自动调整和通信算法的其他改进来提高灵活性;MPI基准测试增加了功能以获得更稳定的基准测试结果,并增加了其他基准测试以减少能耗;集群检查器增加了对intel选择解决方案的支持,以进行仿真和建模以及检查英特尔傲腾DC持久性内存配置;需要的用户可以下载体验
新版功能
1、使用英特尔高级矢量扩展指令512为英特尔至强和英特尔至强融核处理器提供一致的编程,从而实现并扩展。
2、在英特尔Advisor中使用Roofline分析找到影响力很大但未经优化的循环。
3、用高性能的Python加速HPC。
4、了解最新的标准和集成开发环境(IDE):
完整的C ++ 14和最初的C ++ 2017(草稿)
Full Fortran 2008和最初的Fortran 2015(草案)
Python 2.7和3.6
初始OpenMP 5.0(草稿)
Visual Studio 2017集成
5、使用针对MPI,CPU,FPU和内存使用的组合性能快照,快速发现更快代码的高回报机会。
6、通过APT GET,YUM和Conda 轻松访问最新的英特尔性能库和英特尔Python发行版。
7、立即为英特尔®性能库和英特尔®Python发行版使用新的更广泛的重新分发权。
软件特色
1、备受好评的 C++ 和 Fortran 编译器和库
英特尔 Composer XE 是一款注重性能的开发人员工具,它包括英特尔 C++ 和 Fortran 编译器以及线程、数学、多媒体和信号处理性能库。
2、行业领先的英特尔 C++ 和 Fortran 编译器比同类产品快,并且与 Microsoft Visual C++* 和 gcc* 兼容。
3、英特尔 Cilk Plus 和英特尔 线程构建模块提供了并行模型,轻松利用当今和未来的高性能计算系统。
4、行业领先的英特尔 数学内核函数库和英特尔 集成性能基元包含丰富的例程,可提高性能并缩短开发时间。
5、与 Windows*、Linux* 和 Mac OS* X 上各种领先的开发环境和编译器兼容。
6、用于 Linux 和 Windows的创新线程辅助
英特尔 Advisor XE 是一个适用于 C、C++、C# 和 Fortran 开发人员的线程辅助。它能够找出具有大幅并行性能提升潜力的区域,并识别重要的同步问题。
安装步骤
1、用户可以点击本网站提供的下载路径下载得到对应的程序安装包
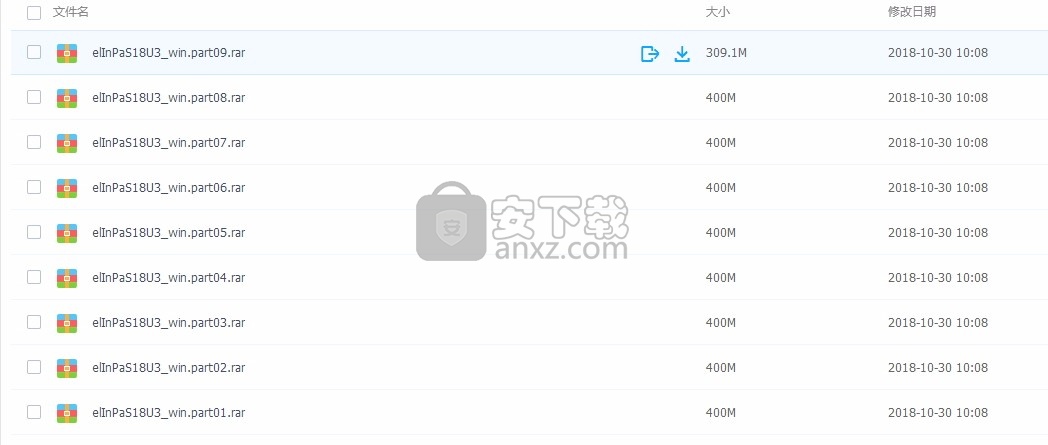
2、只需要使用解压功能将压缩包打开,双击主程序即可进行安装,弹出程序安装界面,点击安装按钮

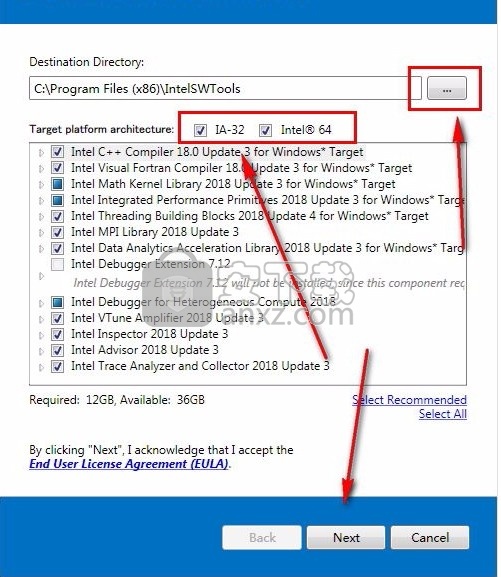
3、弹出以下界面,用户可以直接使用鼠标点击下一步按钮,可以根据您的需要不同的组件进行安装
4、同意上述协议条款,然后继续安装应用程序,点击同意按钮即可

5、提示需要license注册,选择Choose alternative activation即可
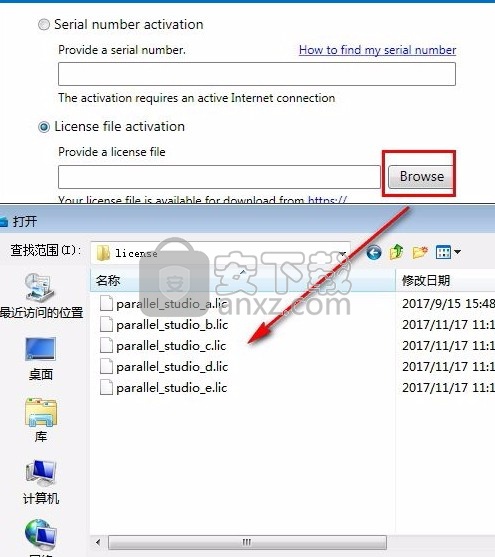
6、点击Browser选择安装包License内的任意.lic文件,点击OK
7、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
方法
1、完成以上操作步骤后,就可以双击应用程序将其打开,此时您就可以得到对应程序
使用说明
自英特尔®C ++编译器19.0.5起的更改(英特尔®C ++编译器19.0.8中的新增功能)
该版本适用于英特尔®编译器2018 Update 8,编译器版本18.0.8。此版本的亮点:
英特尔(R)Parallel Studio XE 2019 Composer Edition包含编译器更新8。
编译器更新6和7对公众不可用。
编译器更新6和7是不是所有客户都可以使用的特殊版本。
更正报告的问题
包括某些功能和安全更新。我们建议针对这些功能和安全更新进行更新。
自英特尔®C ++编译器18.0.4起的更改(英特尔®C ++编译器18.0.5中的新增功能)
注意:此版本不支持macOS * 10.15 Catalina和Xcode * 11.0。 用户将看到有关2019 Up8ate 5和更早版本的英特尔编译器的安装问题,没有Xcode 11集成以及由于不兼容而引起的其他可能的错误。 建议用户推迟升级到macOS * 10.15和Xcode 11,直到我们正式支持此环境。将来的版本将提供对macOS * 10.15和Xcode 11的支持。
支持Xcode 10.3
需要浮动许可证服务器升级
更正报告的问题
包括某些功能和安全更新。我们建议针对这些功能和安全更新进行更新。
自英特尔®C ++编译器18.0.3起的更改(英特尔®C ++编译器19.0.4的新增功能)
支持Xcode 10.2
更正报告的问题
自英特尔®C ++编译器18.0.2起的更改(英特尔®C ++编译器19.0.3中的新增功能)
支持Xcode 10.1
与受支持的Xcode的最新次要版本集成支持
更正报告的问题
自英特尔®C ++编译器19.0.1起的更改(英特尔®C ++编译器18.0.2中的新增功能)
英特尔®C ++编译器19.0更新2包含功能和安全更新。用户应更新到最新版本。
自英特尔®C ++编译器19.0以来的更改(英特尔®C ++编译器18.0.1中的新增功能)
重视#pragma omp simd的安全simd选项
-[Q] x /-[Q] ax /-[m] tune /-[m] arch选项将支持新的代码名称。
macOS * 10.14和Xcode * 10支持
更正报告的问题
自英特尔®C ++编译器18.0起的更改(英特尔®C ++编译器18.0中的新增功能)
支持对OpenMP *并行编译指示的用户定义归纳
支持独家扫描SIMD
-Qopenmp-simd默认设置
-rcd选项已弃用
支持cannonlake选项
不再支持macOS上的32个应用程序
支持新的C ++ 17功能
扩展了对OpenMP * TR6 5.0预览版2的部分支持
新增和更改的编译器选项
如何使用英特尔®C ++编译器
Parallel Studio XE 2019:Mac OS *版英特尔®C ++编译器19.0入门 /documentation_2019/en/compiler_c/ps2019/get_started_mc.htm包含有关如何从命令行和命令行使用英特尔®C ++编译器的信息来自Xcode *。
新增和更改的功能
英特尔®Parallel Studio XE 2019 Update 4需要2.9版或更高版本的英特尔软件许可证管理器才能获得浮动许可证
该版本的英特尔®软件许可管理器已更新至2.9版。您必须先升级到此版本,然后才能使用浮动许可证安装Intel Parallel Studio XE 2019 Update 4。
与支持的Xcode的最新次要版本的集成支持。
重视#pragma omp simd的安全simd选项
当前,“#pragma omp simd”将覆盖FP值和异常安全设置。以下选项更改了旧的行为,甚至为SIMD循环生成了值和异常安全的代码。
Qsimd-honor-fp-model [-]:在向量化SIMD循环时,告诉编译器服从所选浮点模型
Qsimd-serialize-fp-reduction [-]:告诉编译器在向量化SIMD循环时序列化浮点数减少量。
OpenMP SIMD规范和FP模型标志可能在要求上矛盾。编译器的默认设置是遵循OpenMP规范并对循环进行矢量化处理。使用此新标志,程序员可以重写,以便编译器改为遵循FP模型标志并序列化循环。
注1:当使用–qsimd-honor-fp-model且OpenMP SIMD缩减规范是唯一导致整个循环序列化的事物时qsimd-serialize-fp-reduction的结果将导致整个循环的矢量化,除了将串行化的reduce计算。
注意2:此选项不影响循环的自动向量化。
-[Q] x /-[Q] ax /-[m] tune /-[m] arch选项将支持新的代码名称。
支持的代号:cascadelake,kabylake,coffeelake,amberlake,whiskeylake。
编译指示向量的nodynamic_align和vectorlength子句
动态对齐的显式语法
#pragma vector dynamic_align[(pointer)] #pragma vector nodynamic_align
如果未指定任何指针,则编译器会正常运行(自动确定必须对齐的指针或完全不产生剥离循环)。指定了指针后,编译器将为该指针生成剥离循环。使用nodynamic_align子句,编译器将不会生成剥离循环。
#pragma vector vectorlength(vl1,vl2,..,vln)
#pragma vector vectorlength(vl1,vl2, .. , vln)
Vectorizer根据成本模型从列表中选择最佳矢量长度。如果列表中的所有向量长度都不可取,则循环将保持标量。该编译指示不会强制向量化,因此可以安全地用于所有循环。
OpenMP * TR4版本5.0 Preview 2中的功能
现在支持OpenMP *技术报告6:5.0版预览2规范中的语言功能。
包含式扫描的显式语法*
#pragma omp simd[parallel] scan(scan-op: item-list)
#pragma omp inclusive_scan(item-list)
排他扫描的显式语法* 向量执行期间正确计算了前缀和 *语法将在产品版本中重命名
#pragma omp simd[parallel] scan(scan-op: item-list)
#pragma omp inclusive_scan(item-list)
UDI for OpenMP *并行编译指示
#pragma omp declare induction ( induction-id : induction-type :step-type : inductor ) [collector( collector )]
支持的C ++ 17功能
英特尔®C ++编译器19.0在/ Qstd = c ++ 17(Windows *)或-std = c ++ 17(Linux * / macOS *)选项下支持以下功能:
折叠表达式(N4295)
内联变量(P0386R2)
枚举类的构造规则(P0138R2)
删除不赞成使用的动态异常规范(P0003R5)
将异常规格作为类型系统的一部分(P0012R1)
constexpr lambda表达式(P0170R1)
Lambda捕获* this(P0018R3)
constexpr if语句(P0292R2)
结构化绑定(P0217R3)
if和switch(P0305R1)的单独变量和条件
以获取所有受支持功能的最新列表,包括与以前主要编译器版本的比较。
支持的C ++ 14功能
英特尔®C ++编译器19.0在/ Qstd = c ++ 14(Windows *)或-std = c ++ 14(Linux * / macOS *)选项下支持以下功能:
,以获取所有受支持功能的最新列表,包括与以前主要编译器版本的比较。
支持的C ++ 11功能
英特尔®C ++编译器19.0在/ Qstd = c ++ 11(Windows *)或-std = c ++ 11(Linux * / macOS *)选项下支持以下功能:
所有受支持功能的最新列表,包括与该编译器以前的主要版本的比较。
支持C11功能
英特尔®C ++编译器在/ Qstd = c11(Windows *)或-std = c11(Linux * / macOS *)选项下支持C11功能:
C11支持以获取所有受支持功能的最新列表,包括与以前主要编译器版本的比较。
新增和更改的编译器选项
-qopenmp-simd默认设置
默认情况下,使用/ GS读取后,金丝雀字节会立即清除
新的-xcannonlake选项
新的-mtune = cannonlake选项
-rcd选项通过使用最近舍入而不是舍入舍入来启用“快速”浮点数到整数转换。此选项已被弃用。
并行STL,用于C ++ STL的并行和矢量执行
英特尔®C ++编译器与Parallel STL一起安装,该工具是C ++标准库算法的实现,并支持执行策略。
功能/ APi更改
更多算法支持并行和向量执行策略:find_first_of,is_heap,is_heap_until,replace,replace_if。
更多算法支持向量执行策略:remove,remove_if。
更多算法支持并行执行策略:partial_sort。
不再支持
18.0版弃用了英特尔®Cilk™Plus
自英特尔®C ++编译器18.0起,英特尔®Cilk™Plus是已弃用的功能。使用OpenMP *或Intel®线程构建模块(Intel®TBB)代替Intel®Cilk™Plus
支持已删除
删除了对macOS上32位应用程序的支持
从19.0版英特尔®C ++编译器开始,不再支持macOS 32位应用程序。如果要编译32位应用程序,则应使用较早版本的编译器和Xcode * 9.4或更早版本。
已知局限性
缓慢的许可证签出macOS * 10.15 Catalina *
每个源文件在macOS Catalina 10.15上的许可证签出性能大约为1.1秒。与先前版本的macOS相比,此OS的速度降低了10倍。我们正在评估许可证技术的解决方案,但目前还没有根本原因。如果此速度下降是一个问题,请恢复到以前的macOS 10.14,该速度不会发生。
不支持Xcode 10新构建系统
Xcode 10 Beta引入了“新构建系统(默认)”,当前不支持自定义编译器。在XCode 10中构建Intel C ++编译器项目时,您会看到错误“无规则处理文件”。要使用Intel编译器,请切换“项目设置”中的“旧版构建系统”。
并行STL
unseq和par_unseq策略仅对支持“ #pragma omp simd”或“ #pragma simd”的编译器有效。如果提供了随机访问迭代器,则仅对算法的子集支持并行和向量执行,而其余部分将保持串行执行。取决于编译器,zip_iterator可能不适用于unseq和par_unseq策略。
构建Tachyon
对于从Xcode *构建,可能会遇到使用llvm gcc *构建build_with_tbb配置的问题。问题将是找不到libtbb.dylib。在这种情况下,转到“摘要”->“链接的框架和库”部分,然后从 / tbb / lib目录中手动添加libtbb.dylib库。
更新日志
英特尔®Parallel Studio XE 2018 Update 5包括功能和安全更新。用户应更新到最新版本。
修复了安装程序中的安全漏洞。
在英特尔®C / C ++编译器的并行STL中的更多函数中增加了对并行和矢量执行策略的支持。
改进了英特尔®数学内核库中各种功能的性能。
增强了针对英特尔®Advisor的Roofline分析。
在英特尔®Math Kernel Library中的某些例程中针对小问题大小的改进的性能。
在英特尔®C / C ++编译器的更多算法中增加了对并行和/或向量执行策略的支持。
添加了对Xcode * 9.2的支持。
更快的共享内存通信,用于英特尔®MPI库中的集体操作。
英特尔®Advisor可以在同一张图表上可视化多个Roofline分析结果,以比较优化前后的性能。
通过用于多处理数值计算的模块,从Python *代码中调用英特尔®线程构建基块(在技术预览中)。
英特尔®VTune™放大器的应用性能快照增加了新的数据选择选项以及暂停/恢复API支持。
英特尔®数学内核库SparseSyrk和SpMM例程中扩展了英特尔®线程构建模块(Intel®TBB)线程层支持,从而提高了应用程序性能
使用pkg-config文件更轻松地集成英特尔®数学内核库
英特尔®集成性能基元现在使用新的平台感知API支持3D数据过滤和大图像复制
改进了与Microsoft Visual Studio * 2017的集成
现在,“应用程序性能快照”提供了快速的性能概述,而无需在Linux上安装自定义驱动程序
英特尔®Advisor的分层Roofline功能简化了对复杂代码的分析。使用渐进式披露深入研究感兴趣的领域。
英特尔®MPI库2019 Linux技术预览版现已发布。尝试新功能以在混合程序中更好地进行多线程通信并减少延迟。
使用英特尔®跟踪分析器和收集器更快地分析通信不平衡
初始发行
借助用于英特尔®至强®可扩展和英特尔®至强融核™处理器的英特尔®高级矢量扩展512(英特尔®AVX-512)加快应用程序性能。
借助英特尔®Omni-Path体系结构加速MPI应用程序。
使用高性能Python *加速应用程序。
使用英特尔®顾问顾问的屋顶分析,发现具有较高影响力的优化循环。
使用英特尔®VTune™放大器的MPI,CPU,FPU和内存使用性能快照,可以快速发现高回报机会,从而获得更快的代码。添加了MPICH和Cray支持。
紧跟最新的标准和IDE。
完整的C ++ 14和C ++ 2017初稿。
Fortran 2008完整版和Fortran 2015初稿。
Python 2.7和3.6,初始OpenMP 5.0草案。
Microsoft Visual Studio * 2017集成。
人气软件
-

redis desktop manager2020.1中文 32.52 MB
/简体中文 -

s7 200 smart编程软件 187 MB
/简体中文 -

GX Works 2(三菱PLC编程软件) 487 MB
/简体中文 -

CIMCO Edit V8中文 248 MB
/简体中文 -

JetBrains DataGrip 353 MB
/英文 -

Dev C++下载 (TDM-GCC) 83.52 MB
/简体中文 -

TouchWin编辑工具(信捷触摸屏编程软件) 55.69 MB
/简体中文 -
信捷PLC编程工具软件 14.4 MB
/简体中文 -

TLauncher(Minecraft游戏启动器) 16.95 MB
/英文 -

Ardublock中文版(Arduino图形化编程软件) 2.65 MB
/简体中文
 Embarcadero RAD Studio(多功能应用程序开发工具) 12
Embarcadero RAD Studio(多功能应用程序开发工具) 12  猿编程客户端 4.16.0
猿编程客户端 4.16.0  VSCodium(VScode二进制版本) v1.57.1
VSCodium(VScode二进制版本) v1.57.1  aardio(桌面软件快速开发) v35.69.2
aardio(桌面软件快速开发) v35.69.2  一鹤快手(AAuto Studio) v35.69.2
一鹤快手(AAuto Studio) v35.69.2  ILSpy(.Net反编译) v8.0.0.7339 绿色
ILSpy(.Net反编译) v8.0.0.7339 绿色  文本编辑器 Notepad++ v8.1.3 官方中文版
文本编辑器 Notepad++ v8.1.3 官方中文版 






