xilinx vivado 2018.2 Win/Linux
附带安装教程- 软件大小:18432 MB
- 更新日期:2020-04-01 14:54
- 软件语言:简体中文
- 软件类别:3D/CAD软件
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
xilinx vivado design suite HLx Editions 2018.2是一套功能强大的产品加工分析套件,它有一个简称叫xilinx vivado 2018.2,整个应用系统中的功能模块都非常丰富,同时还可以为用户提供非常多的使用便捷;程序提供了一个SoC实力,以IP为中心和以系统为中心的下一代开发环境,该环境完全是为解决系统级集成和实施中的生产力瓶颈而构建的;系统内置了存储器推荐功能,内存的使用随LUT和CLB利用率的提升而增加,时序限制的大小和复杂性直接影响内存需求;新版本还有很多新功能以及特性,在下文中,小编都会详细为大家介绍;需要的用户可以下载体验
新版功能
加快IP创建:将支持仿真的设计变成您可在 Vivado IP Integrator中使用的RTL IP封装并充分利用复杂设计即插即用IP集成设计环境的所有优势。
扩展至 DSP 的系统生成器: 针对您设计的各部分利用 Model Composer 易用性及仿真速度的优势,并将合成的 RTL 导出到您现有的 DSP 设计系统生成器中作为新的自定义模块。
导出至 Vivado HLS:高级特性可通过自动生成您进一步优化算法将需要的一切(包括从仿真中记录的测试向量)在设计、仿真和验证您设计的 Simulink 图形环境与 Vivado HLS 之间提供一条链路。
使用界面映射 RTL 接口: 可便捷地使用图形界面将设计中的输入和输出映射至所支持的 RTL 接口(AXI4-Lite、AXI4-Stream、AXI4-Stream 视频、FIFO 和 Block RAM)以及用于实现方案的视频格式(AXI4-Stream 视频)。
自动测试工作台生成: 对来自测试工作台仿真和生成的测试向量自动生成日志,以验证可执行设计和所生成代码之间的功能对等值.
软件功能
1、一个面向新一代可编程设计的设计工具
赛灵思早在1997 年就推出了ISE 设计套件。ISE套件采用了当时非常具有创新性的基于时序的布局布线引擎,这是1995 年4 月赛灵思收购NeoCAD 获得的。在其后15 年的时间里,随着FPGA 能够执行日趋复杂的功能,赛灵思为ISE 套件增添了许多新技术,包括多语言综合与仿真、IP 集成以及众多编辑和测试实用功能,努力不断从各个方面改进ISE 设计套件。
2、确定性的设计收敛
任何FPGA厂商的集成设计套件的核心都是物理设计流程,包括综合,布局规划、布局、布线、功耗和时序分析、优化和ECO。有了Vivado,赛灵思打造了一个最先进的设计实现流程,可以让客户更快地达到设计收敛的目标。
3、可扩展的数据模型架构
为减少迭代次数和总体设计时间,并提高整体生产力,赛灵思用一个单一的、共享的、可扩展的数据模型建立其设计实现流程,这种框架也常见于当今最先进的ASIC 设计环境。
4、芯片规划层次化,快速综合
Vivado为用户提供了设计分区的功能,可以分别处理综合、执行、验证的设计,使其可以在执行大型项目时,可以成立不同的团队分头设计。同时,新的设计保存功能可以实现时序结果的复用,并且可以实现设计的部分可重配置。
5、多维度分析布局器
上一代FPGA 设计套件采用单维基于时序的布局布线引擎,通过模拟退火算法随机确定工具应在什么地方布置逻辑单元。使用这类工具时,用户先输入时序,模拟退火算法根据时序先从随机初始布局种子开始,然后在本地移动单元,“尽量”与时序要求吻合。
6、功耗优化和分析
当今时代,功耗是FPGA设计中最关键的环节之一。因此,Vivado设计套件的重点就是专注于利用先进的功耗优化技术,为用户的设计提供更大的功耗降低优势
此外,有了这一新的可扩展的数据共享模型,用户可以在设计流程的每一个阶段得到功耗的估值,从而可以在问题发展的前期就能预先进行分析,从而能够在设计流程中,先行解决问题。
7、简化工程变更单(ECO)
增量流量让快速处理小的设计更改成为可能,每次更改后只需重新实现设计的一小部分,使迭代速度更快。它们还能在每个增量变化之后实现性能的表现,从而无需多个设计迭代。
软件特色
主要特性与优势加速设计迭代高层次抽象: 算法主导型构建块以功能性为重点,可为域专家提供至关重要的易用特性,以加速设计探索。
支持向量和矩阵: 可实现基于框架的算法设计,为您转而采用中间低层次实现模型节省宝贵的时间和精力。
应用专用库: 性能优化的DSP、计算机视觉、数学和线性代数库可用作模块,在 Xilinx 器件上进行仿真和实现高性能。
将可综合的 C/C++ 导入为定制模块:能够创建您自己的仿真及代码生成模块,这可为设计差异化算法提供更大的灵活性。
与 Simulink 无缝集成: 与 Simulink 产品系列的模块直接连接,不仅可实现系统级建模和仿真,而且还能够充分利用 Simulink 图形环境的刺激生成和数据可视化功能。
支持整数、浮点和定点支持: 支持 Simulink 中的原生浮动和整数数据类型,以及由 Vivado HLS 提供支持的定点和半数据类型。
变换架构算法自动优化: 不仅可分析 Simulink 中的算法规范和执行自动优化,以实现可针对吞吐量进行优化的微架构,而且还可降低 Block RAM 利用率并实现模块的并行执行。
加快 IP 创建: 将支持仿真的设计变成您可在 Vivado IP Integrator 中使用的 RTL IP 封装并充分利用复杂设计即插即用 IP 集成设计环境的所有优势。
扩展至 DSP 的系统生成器: 针对您设计的各部分利用 Model Composer 易用性及仿真速度的优势,并将合成的 RTL 导出到您现有的 DSP 设计系统生成器中作为新的自定义模块。
导出至 Vivado HLS:高级特性可通过自动生成您进一步优化算法将需要的一切(包括从仿真中记录的测试向量)在设计、仿真和验证您设计的 Simulink 图形环境与 Vivado HLS 之间提供一条链路。
使用界面映射 RTL 接口: 可便捷地使用图形界面将设计中的输入和输出映射至所支持的 RTL 接口(AXI4-Lite、AXI4-Stream、AXI4-Stream 视频、FIFO 和 Block RAM)以及用于实现方案的视频格式(AXI4-Stream 视频)。
自动测试工作台生成: 对来自测试工作台仿真和生成的测试向量自动生成日志,以验证可执行设计和所生成代码之间的功能对等值.
安装步骤
1、用户可以点击本网站提供的下载路径下载得到对应的程序安装包
2、只需要使用解压功能将压缩包打开,双击主程序即可进行安装,弹出程序安装界面
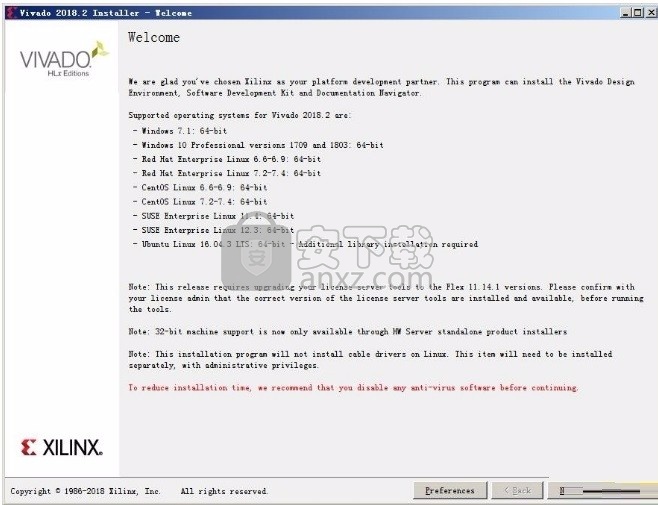
3、同意上述协议条款,然后继续安装应用程序,点击同意按钮即可
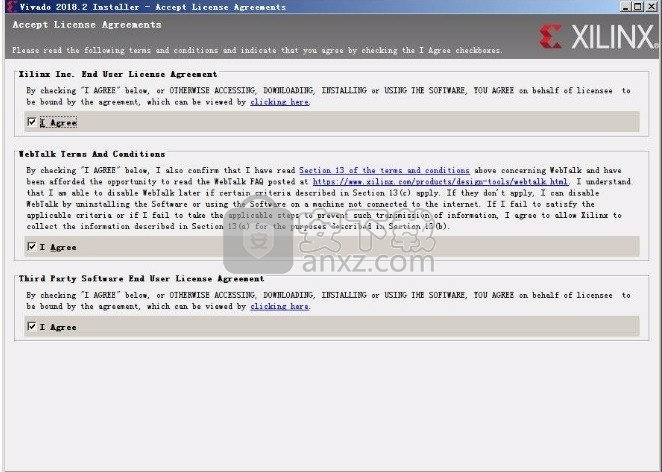
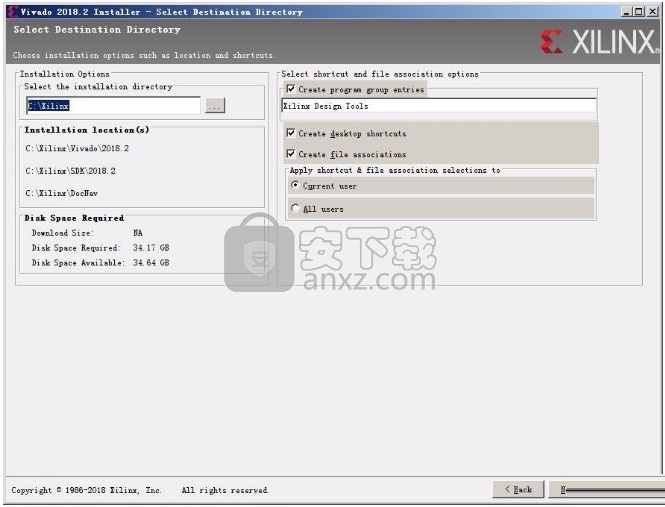
4、弹出以下界面,用户可以直接使用鼠标点击下一步按钮,可以根据您的需要不同的组件进行安装
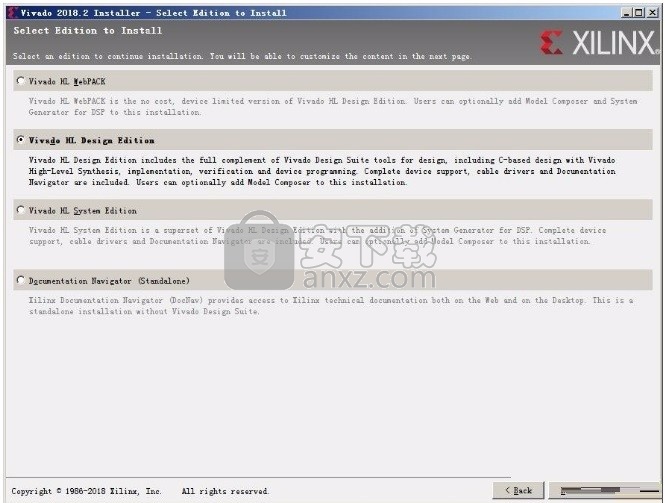
5、现在准备安装主程序,点击安装按钮开始安装
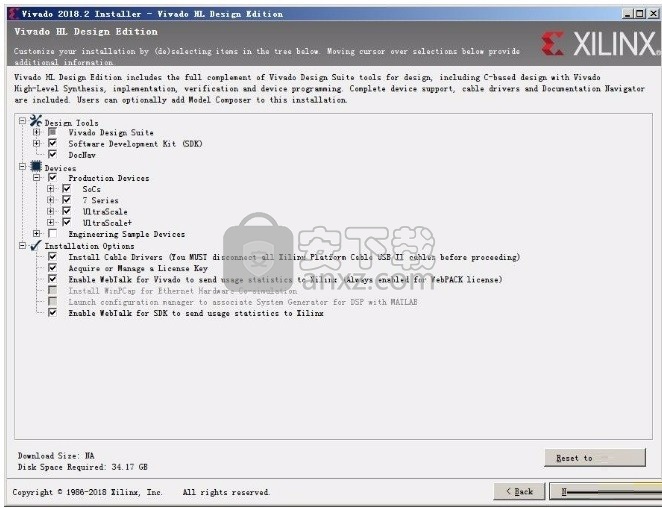
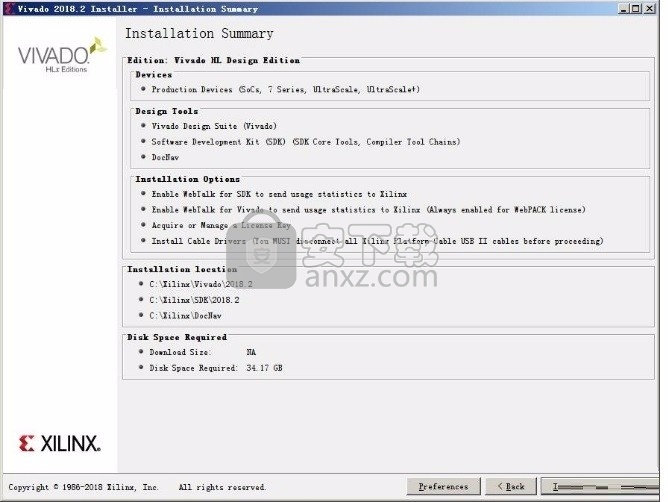
6、弹出应用程序安装进度条加载界面,只需要等待加载完成即可
7、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
使用说明
UltraFast 设计方法为了最大限度地提高系统性能,降低风险,实现更快速和可预测的设计周期,Xilinx 推出了可编程领域的首套综合设计方法。Xilinx 收集了专家用户的最佳实践,并将它们提炼成一套权威的方法指南,即 UltraFast™ 设计方法。
Xilinx 创建了综合而全面的 UltraFast 设计方法指南,涵盖重要原理、特定行为规范、最佳实践以及避免误区的各种方法。在某些主题中,Xilinx 提供了现实生活的使用案例来说明这些概念。这些方法反映了用户在进行 Xilinx 或非 Xilinx 系统的开发过程中所积累的经验和学习心得。
Xilinx 还与联盟成员产业伙伴合作,以便将 UltraFast 设计方法集成到他们的工具和 IP 中。很多 Xilinx 的高级和认证联盟成员已成功完成了 UltraFast 设计方法认证,进一步提高了设计生产力。
Xilinx 面向 Vivado Design Suite HLx 版本发布 UltraFast 高层次生产力设计方法指南。在过去 3 年中,业界领先的 Xilinx 客户不仅开创了支持 C 语言并基于 IP 的设计技术和方法,而且还使其走向了成熟,这些技术方法现在包含在 HLx 版本中,与传统方法相比,实现了 10~15 倍的生产力提升。UltraFast 高层次生产力方法指南重在:
使用并行开发流程实现珍贵的知识产权 (IP),其可实现产品市场差异化
广泛使用基于 C 语言的 IP 开发流程,提供速度比 RTL 仿真快几倍的仿真,以及精确定时、优化的 RTL
使用现有预认证平台、模块和组件级 IP 快速构建系统
使用各种脚本为从准确设计验证到编程型 FPGA 的流程实现高度自动化
传统方法传统设计开发首先是由有经验的设计人员估计如何用新技术实现自己的设计,完成寄存器传输级 (RTL) 的设计采集,通过综合和布局布线执行一些尝试,确认自己的估计,然后继续开展其余部分的设计采集工作。一般完成这项工作的方法是逐次综合每个块,以重复确认设计实现细节可接受。确认设计能提供所需功能的主要方法是仿真该 RTL。尽管 RTL 描述方式具备位准确和周期准确的性质,但这种高度准确性也使得仿真速度过慢且易出错误。只有当设计中的所有块都已经采集到 RTL 中才能够对系统开展完整验证,往往会造成对 RTL 的调整。在系统中的全部块验证完毕后,就可以集中布局布线,早期对时序和占位面积的估算准确性要么完全相符,要么会发现不准确的地方。这也往往会导致对 RTL 的修改,重新启动系统的又一次验证和又一次再实现。设计人员现在往往需要在给定工程中实现数十万行 RTL 代码,把大部分设计时间花在实现的细节工作上。如图 1-1 中所体现,设计人员把更多时间花在实现设计上,而不是设计所有产品保持竞争力所必须的新颖创新的解决方案。无论是采用更新的技术以提升性能,还是采用更缓慢的技术以提供更具竞争力的定价,都意味着大部分 RTL 必须重新写入。设计人员必须重新实现寄存器间的大量逻辑。
shell 概念,即把 I/O 外设和接口采集到独立的设计工程中,与差异化逻辑并行开发和验证。 • 使用基于 C 语言的 IP 仿真,让仿真速度与传统 RTL 仿真相比减少多个数量级,为设计人员提供了设计理想解决方案的时间。 • 运用赛灵思 Vivado® Design Suite,使用基于 C 语言的 IP 开发、 IP 重复使用和标准接口实现时序收敛的高度自动化。 ° 使用 Vivado IP 目录轻松重用您自己的块级和组件级 IP,还能方便地获取已通过验证且已知能在该技术中良好实现的赛灵思 IP。高效设计方法中的所有步骤都能以交互方式执行,或使用命令行脚本执行。所有手工交互的结果都可以保存到脚本,实现从设计仿真直至 FPGA 编程的整个流程的完全自动化。根据 RTL 系统级仿真的设计和运行时间,该流程一般能在任何 RTL 设计仿真完成之前在开发板上生成 FPGA 比特流并测试设计。创建衍生设计时,还将得到更加明显的效率提升。就像修改工具选项一样简单,基于 C 语言的 IP 与不同的器件、技术和时钟速度可轻松对应。完全脚本化的流程加上通过 C 语言综合实现的自动时序收敛,意味着能够迅速地完成衍生设计的验证和组合。
shell 开发流程:通过使用 Vivado IP 集成器和 IP 目录, Vivado Design Suite 能实现快速高效的块级集成。系统性能关键方面中大部分 (包括以细节为重的接口创建、验证和管脚分配)都可拆分以便进行并行开发,并获得各自所需的关注。
基于 C 语言的 IP 开发:使用 RTL 仿真,需要大约一到两天时间才能对完整的一帧视频完成仿真 (取决于设计、主机等条件)。使用 C/C++ 执行同样比特级精度仿真只需大约 10 秒钟。基于 C 语言的开发流程带来的效率优势不容忽视。
系统创建:运用 Vivado IP 集成器和 IP 目录,使用 shell 设计、原有 RTL IP、System Generator IP 和赛灵思 IP 就可以把基于 C 语言的 IP 迅速结合到系统块设计中。自动化接口连接功能和系统创建的脚本化功能意味着系统在整个 IP 开发流程中能够迅速地反复生成。
系统实现:使用经过验证的 shell 设计、自动为器件和时钟频率最优化的基于 C 语言的 IP、经验证的现有 IP,并使用符合业界标准 Arm AMBA® AXI4 协议的接口把它们全部连接起来,您就可以最大程度地节省花在设计收敛上的时间。只需单击几次鼠标或是使用脚本化流程,就可以从系统块设计启动这一流程。
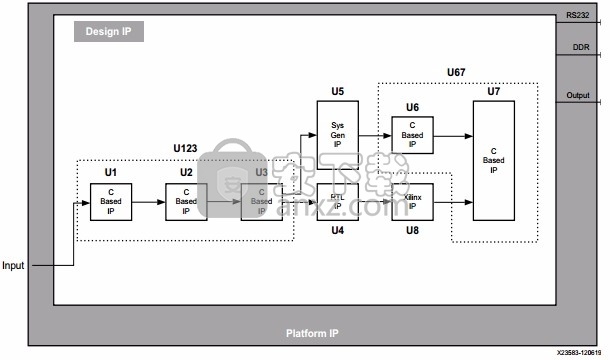
系统验证:系统验证可以使用门级精度的 RTL 仿真和/或通过编程 FPGA 并在开发板上验证设计。由于 RTL 仿真用于验证系统,而非开发过程中用于验证设计的迭代性仿真,故在设计流程结束时只需要一次仿真。
在您开始工程之前,一个重要前提是需要对系统的设计和组合方法有清晰的理解。在任何复杂的系统中都存在通向解决方案的多条路径。这些路径由您的选择而定,包括创建什么样的完整 IP 块、重复使用哪些 IP 块、使用哪些工具和方法验证 IP/集成 IP 到系统中以及使用什么工具和方法检验系统。本章的目的是探讨您做出的系统分区选择和回顾 Vivado® Design Suite 中有助于系统开发流程自动化的关键特性。
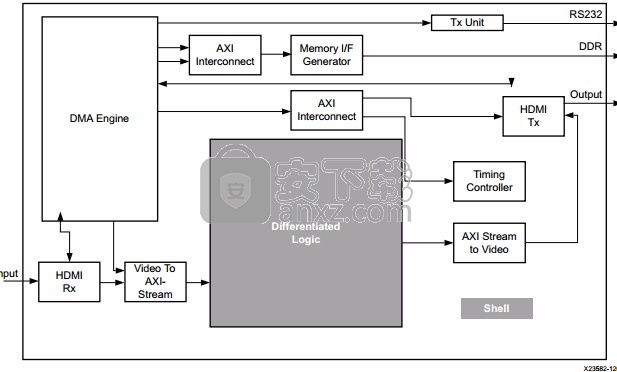
系统分区在典型设计中,位于设计边缘处的逻辑专门用于与外部器件连接,一般使用标准接口。这方面的实例有 DDR、千兆位以太网、PCIe、HDMI、ADC/DAC 和 Aurora 接口。对同一家公司内的多种 FPGA 设计而言,这些接口和用于实现它们的组件一般是标准的。在高效设计方法中,该逻辑与差异化逻辑彼此独立,并被视为 shell。下图所示的即为 shell 块设计示例。下图中心的阴影部分指出了可以添加差异化逻辑或 shell 验证 IP 的区域。
这种方法的主要优势有:
shell 的开发和验证独立于设计的其余部分。
开发板级集成和器件管脚分配由并行开展工作的独立专门团队负责处理。
可保存和重复使用 (甚至重新编辑)该 shell,便于迅速实现多种衍生设计。
差异化逻辑的开发和验证独立于 shell。
预验证的 shell 和差异化逻辑被迅速集成到一个完整系统中。在分区您的系统时,第一项任务就是判断什么要实现在 shell 中,什么要作为差异化逻辑实现。 shell 设计 Shell 设计为高效设计方法提供了两项关键属性:
将标准接口逻辑与差异化逻辑分开,可以让两者的开发和验证并行开发。
创建能够用于迅速开发衍生设计的可重复使用的设计或 shell。理想情况下 shell 应包含设计的标准组成部分,例如设计接口和接口 IP。
不过 shell 也可以包含用于预处理或后处理的块。如果处理功能独立于核设计 IP 且处理功能可在多种设计中使用,更理想的方法是把这些块布局在 shell 内。
这种 shell 重复使用方法支持从 shell 上轻松移除块。无论您决定纳入 shell 设计的逻辑是什么,该 shell 设计的关键属性之一是内部接口,即与内部设计 IP 连接的内部接口应使用标准接口实现。
使用 AXI 等标准内部接口能带来下列特点,能增强 shell 的可重复使用性:
便于 shell 与尚待开发的设计 IP 方便地连接 • 确保在验证 shell 的同时也完成对内部接口的验证
支持使用“IP 集成器与标准接口”介绍的高效集成功能
即便您最初只考虑一个设计,基于平台的方法让您能够在初始设计实现后轻松地创建衍生设计。如需了解关于 shell 开发和验证的详情,
IP 设计 IP 开发流程的主要特性是它只包含能够区分产品与 shell 的 IP。该设计 IP 非标准 IP,需要开发。
大部分开发工作用于运行仿真,以验证设计能否提供正确的功能。
通过排除不会给处于开发中的新功能造成影响的标准块,能最大程度地降低这一工作量和缩短仿真运行时间。
这些标准块应处于 shell 内。下图展示了一个将设计 IP 添加到 shell 设计的完整系统演示。
完成后的系统的关键特性之一在于它可以包含不同来源开发的 IP,例如:
使用 Vivado HLS 由 C/C++ 生成的 IP
使用 System Generator 生成的 IP
使用 RTL 生成的 IP
赛灵思 IP
第三方 IP
在高效设计方法中,最显著的优势之一来自于 C 语言仿真的验证速度。从设计创建的角度来看,通过在开发过程中集中仿真 C 语言块能够带来明显的效率提升。
高速 C 语言仿真便于设计人员迅速开发和验证准确的解决方案。
同时仿真多个 C 语言块有助于彼此验证各自的输出。
如果把多个 C 语言 IP 结合到一个 C 语言仿真中能够更明显地提升总体效率。
突出表现了您在使用 C 语言 IP 时可能遇到的两难局面。块 U1、U2 和 U3 都属于 C 语言 IP,可组合到单个顶层 U123 中。与此类似,块 U6 和 U7 是可以组合到单个 IP 块 U67 中的 C 语言 IP。您可以选择下列两种方法之一:
创建多个较小的 C 语言 IP 块,例如 U1、 U2、 U3、 U6 和 U7。
创建几个大型 C 语言 IP 块,例如上图中列出的 U123 和 U67。从设计集成的角度出发,这两种方法之间并无区别。如果 IP 块是使用 AXI 接口创建的,使用 IP 集成器就能够方便地把它们集成到一起。
对刚刚接触基于 C 语言 IP 开发的设计人员来说,较为理智的做法可能是使用较小块开展工作、学习如何独立最优化每个小块、然后把多个小型 IP 块集成到一起。
对已经熟悉 C 语言 IP 开发的设计人员而言,较为方便的做法是生成几个大型 C 语言 IP 块。
重要提示:关键的效率优势在于能够在开发过程中把尽量多的 C 语言 IP 块集中到一个 C 语言仿真中进行仿真。
在上述情况下,用于验证块 U1、U2 和 U3 的 C 语言测试平台同样用于验证 U123。
IP 生成的区别在于您或是在 Vivado HLS 中把 C 语言综合的顶层设置为 U123 功能,或是设置为 U1 功能,随后还有 U2 和 U3。
不管采用什么方法创建这些 IP 块,每个 IP 块都需要按下列方法进行独立验证:
用 C/C++ 开发的 IP 使用 Vivado HLS 的 C/RTL 协同仿真功能进行验证,方便采用用于验证基于 C 语言 IP 的同一 C 语言测试平台来验证 RTL。
用 System Generator 开发的 IP 采用 System Generator 中提供的 MathWorks Simulink 设计环境进行验证。 Simulink 环境通过使用预定义的仿真元,即可轻松生成复杂的输入激励并分析复杂的结果。
用 C/C++ 以及通过传统 RTL 生成的 IP 都能导入到系 System Generator 环境中,发挥这一验证功能的作用。
对用 RTL 生成的 IP,用户必须创建 RTL 测试平台来验证该 IP。
赛灵思和第三方供应商提供的 IP 已预先验证,不过您可能希望根据自己的配置参数集合创建测试平台来验证其运行。
在 IP 上使用标准 AXI 接口能实现 IP 彼此之间以及 IP 与 shell 设计的迅速集成。
IP 目录具有下列特性:
内含大约 200 个由赛灵思提供的 IP
能使用 System Generator、原有 RTL 和赛灵思合作伙伴 IP 加以强化。
内置大量接口 IP,支持使用原有 RTL IP,在创建 shell 时广泛使用。
是系统集成过程中所有 IP 块的来源。
在系统集成和验证过程中提供 RTL 实现功能。
在 shell 开发过程中该 shell 可使用 IP 目录提供的 IP 在 IP 集成器中组合。
IP 目录中提供了该 AXI 互联 IP,可以手工添加,不过 IP 集成器能自动完成这项任务。此外,如果把最终块设计保存为脚本, Tcl 命令就会指出需要连接到哪些引脚。
提示:当升级到新版本的 Vivado Design Suite 和赛灵思 IP 时,应重新运行脚本,从而确保其使用的是最新的互联逻辑。
在您的设计中使用标准接口的最后一种情况是为开发板级连接提供的设计辅助功能。
除了可以选择目标器件, Vivado Design Suite 还可以选择目标板。
IP 集成器具有开发板感知能力,能够自动完成开发板级连接。在得到设计人员确认后, IP 集成器能自动完成 IP 与 FPGA 引脚之间的连接 (开发板连接)。
人气软件
-

理正勘察CAD 8.5pb2 153.65 MB
/简体中文 -

浩辰CAD 2020(GstarCAD2020) 32/64位 227.88 MB
/简体中文 -

CAXA CAD 2020 885.0 MB
/简体中文 -

天正建筑完整图库 103 MB
/简体中文 -

Bentley Acute3D Viewer 32.0 MB
/英文 -

草图大师2020中文 215.88 MB
/简体中文 -

vray for 3dmax 2018(vray渲染器 3.6) 318.19 MB
/简体中文 -
cnckad 32位/64位 2181 MB
/简体中文 -

Mastercam X9中文 1485 MB
/简体中文 -

BodyPaint 3D R18中文 6861 MB
/简体中文
 lumion11.0中文(建筑渲染软件) 11.0
lumion11.0中文(建筑渲染软件) 11.0  广联达CAD快速看图 6.0.0.93
广联达CAD快速看图 6.0.0.93  Blockbench(3D模型设计) v4.7.4
Blockbench(3D模型设计) v4.7.4  DATAKIT crossmanager 2018.2中文 32位/64位 附破解教程
DATAKIT crossmanager 2018.2中文 32位/64位 附破解教程  DesignCAD 3D Max(3D建模和2D制图软件) v24.0 免费版
DesignCAD 3D Max(3D建模和2D制图软件) v24.0 免费版  simlab composer 7 v7.1.0 附安装程序
simlab composer 7 v7.1.0 附安装程序  houdini13 v13.0.198.21 64 位最新版
houdini13 v13.0.198.21 64 位最新版