Xilinx Vivado 2017.4 Win/Linux(内置两个版本)
附带安装教程- 软件大小:18514 MB
- 更新日期:2020-04-01 15:30
- 软件语言:简体中文
- 软件类别:3D/CAD软件
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
Vivado 2017.4是一套功能强大的产品加工分析套件,同时该程序系统中还内置了先进的仿真技术以及超级算法,从而为用户提供一系列的高效设计方法,提供的生产力优势关键在于使用shell模块,一个shell设计包含所有的标准接口和处理块,提供核设计IP与系统其余部分的连接,并与核设计IP并行开发;这种整合shell设计的方法可提供重要的效率提升;它能够实现独立于核设计进行的设计接口和I/O管脚分配的开发,该方法可在核设计IP就绪之前开展设计接口的验证;由于设计缩短了接口的验证时间;它并不包含一般情况下占据大部分系统逻辑的核设计IP;由此引入了一套高效的设计重复使用方法,实现轻松创建衍生设计;新版本加速了高级设计,整个设计过程无需额外付费即可进行部分重新配置,新的HLx版本为设计团队提供了利用基于C的设计和优化的重用,IP子系统重用,集成自动化和加速设计完成所需的工具和方法;需要的用户可以下载体验
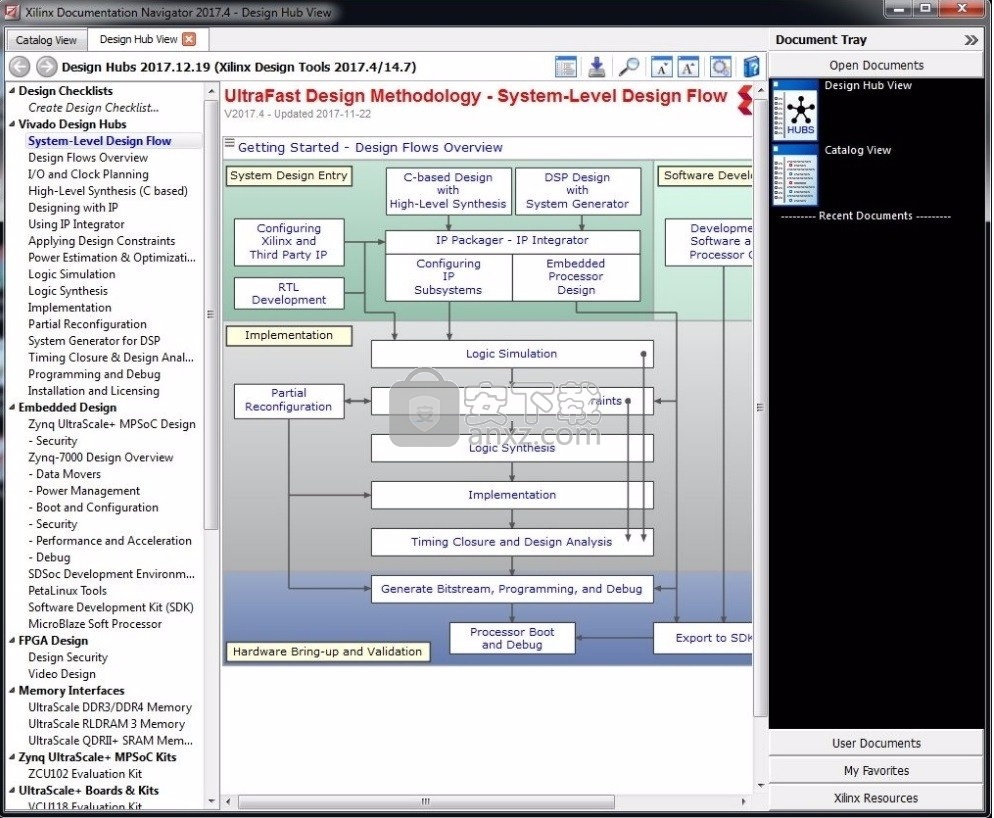
新版功能
Vivado提供了一系列设计输入,时序分析,硬件调试和仿真功能,所有这些功能都包含在单个最新的集成设计环境(IDE)中。该流程满足了所有受支持模拟器的集成和企业验证需求。
Vivado使行为,合成后和实施后(功能或时序)模拟为完全集成Vivado模拟器和3 次方HDL仿真。在设计周期的早期进行仿真所花费的时间有助于及早发现问题,并且与流程的后期相比,可以大大减少周转时间。
为了在用户验证环境中提供灵活性,Vivado提供了对集成环境的支持,并提供了与外部验证设置一起使用的脚本。
Vivado提供了在用户环境中为受支持的模拟器编译模拟库的功能,从而可以重新使用已编译的库。
能够在设计过程的不同阶段模拟和验证设计完整性
行为模拟
合成后功能和时序仿真,实施后功能和时序仿真
便携式集成仿真环境,对所有模拟器使用一致的三步过程(编译,精心制作,模拟)进行统一的模拟集成
仿真脚本生成的企业3 次聚会模拟器
IP生成步骤创建模拟脚本
启用了脚本生成功能的用户可以整合到用户环境中
Vivado集成设计环境(IDE)为用户提供了使用仿真集探索多种仿真策略的能力。仿真集允许用户在Vivado IDE中管理验证过程,并根据验证需求创建不同的仿真流程。
Vivado集成设计环境(IDE)为用户提供了使用仿真集探索多种仿真策略的能力。仿真集允许用户在Vivado IDE中管理验证过程,并根据验证需求创建不同的仿真流程。
灵活的仿真环境,探索不同的仿真策略,不同的Verilog定义
更改源(测试台,头文件…)并排比较多个模拟
同时运行行为和合成后仿真,组织模拟流程
可以为模块级仿真和系统级仿真创建单独的仿真集
软件特色
一、加速高级设计
1、采用Vivado高级综合的软件定义IP生成。
2、与Vivado IP Integrator进行基于块的IP集成。
3、基于模型的DSP与模型编译器和系统生成器的设计集成。
二、加速验证
1、Vivado逻辑仿真
2、综合混合语言模拟器
3、集成和独立编程和调试环境
4、使用Vivado HLS,使用C,C++或SystemC 加速验证>100X
5、验证IP
三、加速实施
1、实施速度提高4倍
2、20%更好的设计密度
3、高端的低端和中端高达3速的性能优势和高端的35%Power Advantage
Xilinx的验证IP(VIP)产品组合使用户能够轻松,快速且有效地在仿真环境中验证和调试其设计。
验证IP核是专用的验证模型,其目的是确保正确的互操作性和系统行为。
EDA行业的公司为基于标准的接口(AXI,PCIe,SAS,SATA,USB,HDMI,ENET等)开发VIP。使用VIP的优势包括可重复使用,从而提高了设计质量并减少了计划时间。
赛灵思的VIP内核是基于SystemVerilog的仿真模型,可提供带有ARM许可断言的完整AXI协议检查,支持所有主要仿真器,并且免费包含在Vivado中。
赛灵思提供VIP,用于使用AXI组件级别(AXI-MM,AXI_Stream)和处理系统(Zynq®-7000)设计的设计。
安装步骤
1、用户可以点击本网站提供的下载路径下载得到对应的程序安装包
2、只需要使用解压功能将压缩包打开,双击主程序即可进行安装
3、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
使用说明
IP 集成器能自动将 IP 集成到块级原理图。其他特性包括使用验证功能的设计规则检查和为 AXI 互联 IP 自动添加时钟和复位逻辑。发挥这一自动化功能的优势,落实成效显著的 shell 方法的关键在于对片上通信使用标准接口和 AXI 接口。
shell 设计 shell 设计仅包括设计边缘,如上图所示,而且必须采用易于重新利用设计的形式。 shell 将保存并重新打开以构成多个工程的基础。为实现如上图所示的流程所需的设计重用层次, shell 设计应作为块设计采集到 IP 集成器中,以便轻松保存和重新打开,从而构建其它设计工程的基础。组装现有 IP 在 IP 集成器中使用 IP 目录提供的 IP,以块设计的形式组装 shell 设计。重要提示:作为创建 shell 的的准备,请封装现有 RTL 或任何您希望在 shell 设计中使用的具体公司 IP,以备 IP 目录使用。这样您就可以将 IP 添加到 shell 块设计中。
创建 Vivado 工程时:
将工程定义为一个 RTL 工程并选择“Do not specify any sources at this time”。 shell 设计源就是您封装在 IP 目录中的 IP。
理想情况下,选择该目标板作为赛灵思开发板。赛灵思开发板所用器件的 I/O 已完成配置。这样,在您已开发自己的定制板时能以最短时间开展工作,您也可以利用 IP 集成器中的设计人员自动化 (Designer Automation) 功能进行 I/O 连接。如未指定赛灵思开发板为目标板,您需要为目标器件指定 I/O 连接。
如果在开发进程中使用了您的定制板,建议您创建一个开发板文件,其中包含开发板连接详细信息,并在 IP 集成器内实现设计自动化功能,这将极大地简化开发板级连接。
创建工程后,使用 Flow Navigator 中的“Create Block Design”按钮,打开 IP 集成器并创建一个新的“块设计 (Block Design)”。
在 IP 集成器窗口中,指定您 IP 资源库的源并使用“Add Ip”按钮开始进行按钮开始进行 shell 的组合。
shell 完成后,使用 write_bd_tcl 命令把整个块设计保存为 Tcl 脚本。脚本包含从头开始重新生成模设计所需的一切。
块设计和 Vivado 工程已保存并准备好用于验证和系统开发的后续阶段。在 Documentation Navigator 的“Design Hubs” (设计中心)标签中提供了有关管脚分配、 IP 集成器以及其它功能的进一步信息。
Shell 验证完成 shell 设计创建后就可以进行 shell 验证。在验证过程中, shell 设计会重新打开,并将验证 IP 添加到设计中,以确认接口正常工作。 shell 验证验证验证 shell 设计的第一步是使用以下两个选项之一创建新的验证工程。
打开用于 shell 设计的 Vivado 工程,使用“File > Save Project As”在新工程中保存 shell 设计。
创建一个新的 Vivado RTL 工程 (无 RTL 源)和相同的目标器件或开发板。然后选择“Create Block Design”,并在控制台中找到使用 write_bd_tcl 保存的 Tcl 脚本,用于在新工程中重新生成 shell 块设计。
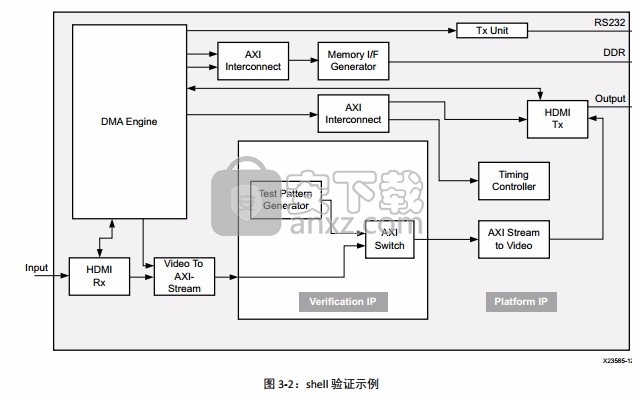
可能需要使用多个验证工程来确保验证设计的复杂性可控。下图所示的即为 shell 示例验证设计。本示例仅测试单个接口。
验证 IP 将验证 IP 从 Vivado IP 目录中添加到 shell 设计,以验证设计。本指南中讨论的所有技巧都可用于开发验证 IP:RTL、 System Generator、或基于 C 语言的 IP。下面的示例显示如果采用标准 AXI 接口 IP,如何使用一个小型 C 语言文件快速创建例如 AXI4-Stream 流接口上包含 N 个样本输出的一个 HANN 窗口。如下面代码示例所示,只要将接口指令从 axis 改为 m_axi,就能够实现一个 AXI 存储器映射接口:
验证 shell 如果在仿真源中添加了顶层测试平台,在进行 FPGA 编程前就能够通过仿真验证 shell 设计。使用 RTL 仿真进行 shell 验证需要创建 RTL 测试平台。使用该测试平台对完全集成的设计进行验证。
如果使用多个验证工程来验证 shell,应扩展同样的测试平台以验证所有接口。
为验证 FPGA 上的具体接口,可在设计中添加额外的信号级调试探针。在块设计中工作时,右键单击菜单便可轻松标记网络用于调试。在硬件运行中,可对标记用于调试的信号进行分析:设计中添加了 ILA 核,用以从 FPGA 采集和扫描出信号,以供分析
最终设计随后通过 Vivado 设计流程处理为比特流。shell 验证完毕后,对 shell 设计进行的任何修改都应传回最初的源 shell 设计项目,但对验证 IP 执行的修改除外。至此, shell 设计已准备就绪,可用于核设计 IP 的集成。
在高效设计流程中,生成核设计 IP 的主要方式是使用基于 C 语言的 IP 和通过高层次综合 (HLS) 把 C 语言代码转化为 RTL。基于 C 语言的 IP 开发流程提供了下列优势:
C 语言验证提供的一流仿真速度
自动生成时序精确的经最优化 RTL
能够使用库中的现有 C 语言 IP
能使用 IP 集成器轻松地把生成的 RTL IP 集成到完整的系统中本章讨论如何创建、验证、综合、分析、最优化基于 C 语言的 IP 并将其封装到 IP 中以供 IP 目录使用。
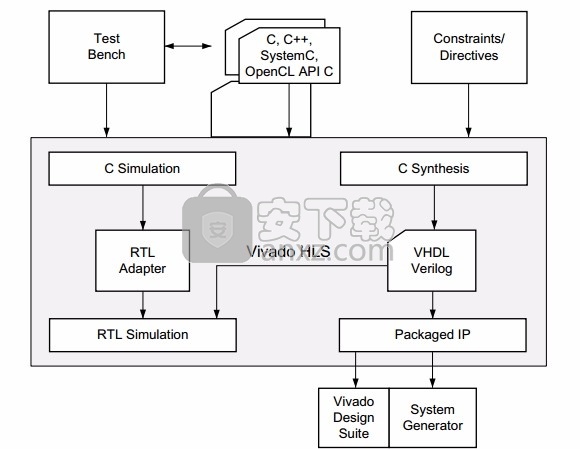
实现这一工作的方法就是 Vivado® 高层次综合 (HLS),它是一种由 Vivado Design Suite 提供的工具。 Vivado HLS 设计流程见下图所示。设计流程步骤包括:
1. 编译、执行 (仿真)和调试 C 语言算法。注释:在高层次综合中,运行编译后的 C 语言程序被称为 C 语言仿真。运行 C 语言程序,仿真该功能,以验证算法功能正常。
2. 在 RTL 实现中综合 C 语言程序,可选择使用用户最优化指令。
3. 生成综合性报告并分析设计。
4. 使用按钮式流程验证 RTL 设计实现。
5. 将 RTL 设计实现封装为一套选定的 IP 格式
快速 C 验证与在 RTL 中仿真相比,在 C 语言中仿真相同的算法速度可快上数倍。以标准的视频算法为例。
典型的 C 语言视频算法先处理完整的视频数据帧,然后把输出图像与基准图像做比较,确认结果的正确性。这个算法的 C 语言仿真一般耗时 10 到 20 秒。
RTL 实现的仿真通常需要几个小时到一天 (数天)不等,具体取决于帧的数量和设计的复杂性。借助软件仿真速度的优势,采用 C 语言进行的设计开发越多,生产效率就越高。
设计人员正是在这一层面上开展实际的设计工作:调整算法、数据类型、比特宽度以验证和确认设计的正确性。
该流程的其余部分属于开发工作:使用工具链在 FPGA 中实现正确的设计。
Vivado Design Suite 和高效设计方法提供的优势在于为设计流程带来了高度自动化。
在初步 FPGA 设计实现后,马上创建一个完整的新比特流为 FPGA 编程的做法并非罕见。
为最大限度提升基于 C 语言的 IP 流程的效率,应了解以下几点:
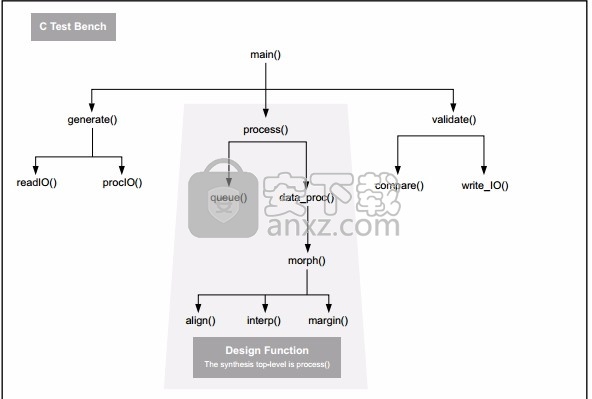
C 测试平台每一个 C 语言程序的顶层都是 main() 函数。Vivado HLS 用于综合 main() 以下的每一个单项函数。
需要 Vivado HLS 综合的函数称之为“设计函数” (Design Function)。
设计函数下的所有函数都通过 Vivado HLS 综合。
设计函数层级外的全部内容被称为“C 测试平台”。
C 测试平台包括 main() 下的所有 C 语言代码,用于为设计函数提供输入数据以及从设计函数接受输出数据以确认其准确性。
Vivado HLS 设计流程中新用户可能犯下的最大错误是不使用 C 测试平台和不执行 C 语言仿真就综合自己的 C 语言代码。这一情况突出体现在下面的代码中。在本嵌套循环示例中有哪些错误?

该代码综合结果与期望的结果不符,因为条件语句求值为 FALSE 且 J 在 LOOP_J 第一次迭代结束时设置为 19。该条件语句的正确表达应为 j==0 且 j==19 (使用 == 取代 =)。
前述代码示例能够毫无问题地编译、执行和综合。但是如果只是草率地目测评估该代码,该代码将无法发挥预期的作用。
在开发人员每天不断使用 C/C++、Perl、Tcl、Python、Verilog 和 VHDL 语言中的一种或多种的时代,不仅难以察觉此类小错误,更难以发现功能性错误,而且在综合后发掘它们难度极大、极为耗时。
C 测试平台仅仅是一个调用需要综合的 C 语言函数的程序,用于提供测试数据和测试输出的正确性。
它可以在综合前编译和运行并且在综合前验证预期结果。您在一开始可能会认为直接进行综合能节省时间。
但在您的设计方法中使用 C 测试平台带来的好处比创建测试平台所用的时间更有价值。自检测试平台 Vivado HLS 支持在综合前开展 C 语言仿真,以验证 C 语言算法。
同时支持在综合后进行 C/RTL 协同仿真,以验证 RTL 设计实现。在两种情况下,Vivado HLS 均使用函数 main() 的 return 值确认结果的正确性。
理想的 C 测试平台应有下面的代码示例中所示的结果检查属性。
该函数供综合使用的输出保存在文件 results.dat 中并与正确结果和预期的结果比对,也就是本示例中所谓的“理想”结果。

在本 Vivado HLS 设计流程中,函数 main() 的 return 代表下述意义:
零值:结果正确。
非零值:结果不正确。建议:由于系统环境 (例如 Linux、 Windows 或 Tcl)用于解读 main() 函数的返回值,赛灵思建议出于移植性和安全性考虑,把返回值约束为 8 位范围。
通过使用自检测试平台,您无需创建 RTL 测试平台来验证 Vivado HLS 的输出的正确性。
用于 C 语言仿真的测试平台在 C/RTL 协同仿真过程中也会自动使用,然后用该测试平台验证综合后的结果。
C 语言中有多种途径检查结果的有效性。在上面的示例中,该函数供综合使用的输出保存为文件 result.dat,并与含预期结果的文件做比较。
这些结果还可以与未标记成用于综合的相同函数做比较 (测试平台运行时在软件内执行)或与测试平台计算的值做比较。
重要提示:如果测试平台的函数 main() 中没有 return 语句, C 语言标准会把 return 值设为零。因此 C 语言和 C/RTL 协同仿真往往会报告仿真通过,哪怕结果是错误的。检查结果,仅当结果正确时才返回零值。
花时间创建自检测试平台可确保 C 语言代码中没有明显错误,无需创建 RTL 测试平台以验证综合得到的输出的正确性。比特精度数据类型随 Vivado HLS 提供有任意精度数据类型,可指定任意宽度的变量。
例如可以把变量定义为 12 位、22 位或 34 位宽度。使用标准的 C 语言数据类型,这些变量分别应为 16 位、32 位和 64 位。
使用标准的 C 语言数据类型往往造成使用不必要的硬件来实现所需的精度。例如仅需要 34 位时却用 64 位硬件来实现。
使用任意精度数据类型的一个更明显的优势是使用这些新的比特宽度仿真 C 语言算法,分析比特精度结果。
例如您可能想设计一种 10 位输入和 14 位输出的滤波器,同时您可能判定该设计可使用 24 位累加器。
运行 C 语言仿真,在数分钟内即可用数万样本对滤波器进行仿真,快速确定输出的信噪比是否可接受。
您很快就能够判断是否累加器过小,或验证使用更小、更高效的累加器是否仍然提供所需的精度。
重要提示:比特精度 C 语言仿真是验证设计的最快途径。
高效设计方法的特点是使用标准 C 语言数据类型启动您的初始设计,然后确认算法性能是否符合设计。
随后移植 C 语言代码,以使用任意精度数据类型。
对于这种移植到硬件效率更高的数据类型上的操作,只有在能够用 C 测试平台检查结果的情况下才能够安全且高效地执行。
这样您可以迅速地验证较小但更高效的数据类型是否能够胜任。当您已经熟悉任意精度类型的使用,一般就可以在新的 C 语言工程初期就使用任意精度数据类型。
使用 C 测试平台的优势,以及在您的设计方法中不使用它所带来的效率损失,都非常显而易见。
中的链接里描述的 Vivado HLS 示例均提供有 C、C++ 或 SystemC 测试平台。这些示例经复制和修改可用于创建 C 测试平台。其中包括使用任意精度数据类型的 C 语言函数。
C 语言对综合的支持理解综合支持哪些语言是 Vivado HLS UltraFast 设计方法的重要组成部分。
Vivado HLS 为 C、 C++ 和 SystemC 提供全面支持。 C 语言仿真可全面支持,但不能够把每一种描述都综合为等效的 RTL 设计实现。
在审核用于实现在 FPGA 中的代码时应牢记两个原则:
FPGA 有固定数量的资源。功能必须在编译时固定。硬件中的对象不能动态创建和删除。
与 FPGA 的全部通信必须通过输入输出端口进行。 FPGA 不具备底层操作系统 (OS) 或操作系统资源。
不支持的结构系统调用综合不支持系统调用。这些调用用于与运行 C 语言程序的操作系统交互。
在 FPGA 中不存在需要与之通信的底层操作系统。系统调用的示例有“time()”和“printf()”。部分常用函数会被 Vivado HLS 自动忽略,因此需要把它们从代码中去除。这些函数是
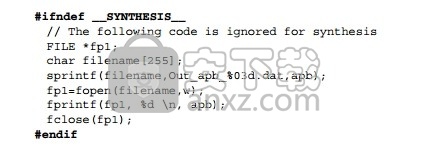
除了移除任何不受支持的代码之外,还有一种方法是禁止其进入综合。 __SYNTHESIS__ 宏在执行综合时由 Vivado HLS 自动定义。该宏可用于在运行 C 语言仿真时包含代码,在运行综合时排除该代码。

注释:只在需要综合的代码中使用 __SYNTHESIS__ 宏。请勿在测试平台中使用该宏,因为 C 语言仿真或 C/RTL 协同仿真不会遵从该宏。如果需要操作系统提供信息,该数据必须作为实参传递给顶层函数供综合使用。
随后就是系统其余部分的任务,将该信息提供给综合后的 IP 块。
这一工作一般的完成方法是把该数据端口实现为连接到 CPU 的 AXI4-Lite 接口。动态对象动态对象不能综合。
函数调用 malloc() 和 alloc()、预处理器 free() 和 C++ new 以及 delete 能够动态地创建或删除操作系统存储器映射中的存储器资源。
FPGA 中可用的唯一存储器资源是块 RAM 和寄存器。块 RAM 是阵列综合时创建的,必须在一个或者数个时钟周期间保持阵列中的值。
当在一个或者数个时钟周期内必须保持变量存储的值时,就要创建寄存器。必须使用固定大小的阵列或变量替代任何动态存储器分配。
和用于动态存储器使用的限制一样,Vivado HLS 不支持动态创建或删除的 C++ 对象(用于综合)。
这包括动态多态性和动态虚拟函数调用。可能形成新硬件的新函数不能在运行中动态地创建。
出于类似原因,综合中也不支持递归。所有对象在编译时必须有已知的大小。在使用模板时可有限地支持递归
有限支持的结构顶层函数支持使用模板进行综合,但不支持用于顶层函数。
C++ 类对象不能在综合中直接用于顶层。该类必须例化为顶层函数。
综合中支持指针到指针的指向,但如果用作顶层函数的实参就不支持。
指针支持 Vivado HLS 支持原生 C 语言类型间的指针转型,但不支持一般性的指针转型,比如为区别结构类型而在指针间进行转型。
Vivado HLS 支持指针阵列,只要每一个指针指向 scalar 或 scalar 阵列。指针阵列不能指向其他指针。
递归在 FPGA 中只支持使用模板的递归。综合中执行递归的关键是使用尺寸为 1 的终端类在递归中实现最终调用。存储器函数 memcpy() 和 memset() 均受支持,但其限制条件是必须使用 const 值。
memcpy():用于总线突发运行或使用恒值的阵列初始化。
memcpy 函数只能用于把值复制到用于顶层函数的参数或从中将值复制出来。
memset():用于使用常量设置值进行聚合初始化。
任何不支持用于综合的代码或任何有限支持用于综合的代码必须在能够综合前加以修改。
使用经硬件最优化的 C 语言库 Vivado HLS 为常用的 C 语言函数提供了一定数量的 C 语言库。 C 语言库中提供的函数一般经过预先最优化,可确保在综合时得到高性能和高效率设计实现。
“高层次综合 C 语言库”对随 Vivado HLS 提供的所有 C 语言库进行了充分介绍,但作为您方法的一部分,强烈推荐您对 C 语言库中提供的 C 语言函数进行深入了解。 Vivado HLS 包含下列 C 语言库:
人气软件
-

理正勘察CAD 8.5pb2 153.65 MB
/简体中文 -

浩辰CAD 2020(GstarCAD2020) 32/64位 227.88 MB
/简体中文 -

CAXA CAD 2020 885.0 MB
/简体中文 -

天正建筑完整图库 103 MB
/简体中文 -

Bentley Acute3D Viewer 32.0 MB
/英文 -

草图大师2020中文 215.88 MB
/简体中文 -

vray for 3dmax 2018(vray渲染器 3.6) 318.19 MB
/简体中文 -
cnckad 32位/64位 2181 MB
/简体中文 -

Mastercam X9中文 1485 MB
/简体中文 -

BodyPaint 3D R18中文 6861 MB
/简体中文
 lumion11.0中文(建筑渲染软件) 11.0
lumion11.0中文(建筑渲染软件) 11.0  广联达CAD快速看图 6.0.0.93
广联达CAD快速看图 6.0.0.93  Blockbench(3D模型设计) v4.7.4
Blockbench(3D模型设计) v4.7.4  DATAKIT crossmanager 2018.2中文 32位/64位 附破解教程
DATAKIT crossmanager 2018.2中文 32位/64位 附破解教程  DesignCAD 3D Max(3D建模和2D制图软件) v24.0 免费版
DesignCAD 3D Max(3D建模和2D制图软件) v24.0 免费版  simlab composer 7 v7.1.0 附安装程序
simlab composer 7 v7.1.0 附安装程序  houdini13 v13.0.198.21 64 位最新版
houdini13 v13.0.198.21 64 位最新版