

Balabolka(语音阅读器)
v2.15.0.805- 软件大小:22.71 MB
- 更新日期:2021-11-18 14:55
- 软件语言:简体中文
- 软件类别:电子阅读
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
Balabolka是一款将文字以语音的方式呈现出来的软件,Balabolka可以使用系统上安装的所有计算机语言。可以使用Balabolka顶部附近工具栏上的标准播放、暂停、停止按钮来控制语音。该程序可以读取剪贴板内容,查看文档中的文本,自定义字体和背景颜色,控制从系统托盘或全局热键读取。支持的文件格式:AZW,AZW3,CHM,DjVu,DOC,DOCX,EML,EPUB,FB2,FB3,HTML,LIT,MOBI,ODP,ODS,ODT,PDB, PDF,PPT,PPTX,PRC,RTF,TCR,WPD,XLS,XLSX。 IFilter接口可用于扩展名未知的文件。通过从“文件”菜单中选择“文件、保存音频文件”或“文件、拆分并转换为音频文件”,可以将屏幕上的文本保存为WAV,MP3,MP4,OGG或WMA文件。Balabolka可以将同步文本保存在外部LRC文件或音频文件内的MP3标签中。当在计算机或现代数字音频播放器上播放音频文件时,文本将同步显示(与歌曲的歌词相同)。该程序可以使用各种版本的Microsoft Speech API(SAPI)和Microsoft Speech Platform,它允许改变声音的参数,包括速率和音高,用户可以应用特殊替换列表来提高语音清晰度的质量,当您想要更改单词的拼写或分隔音节时,此功能非常实用。
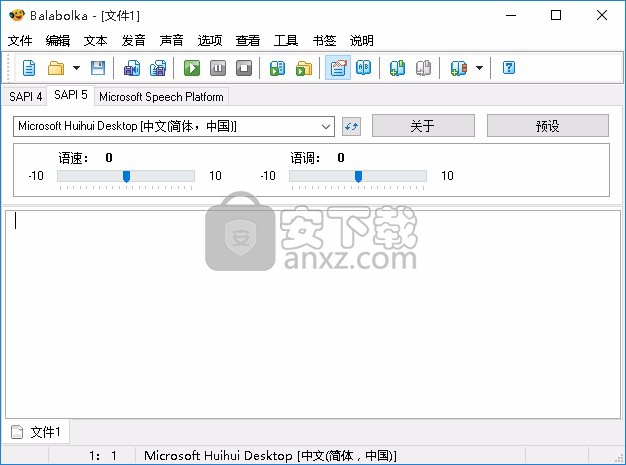
软件功能
声音
语音应用程序编程接口或SAPI由Microsoft开发,允许在Windows应用程序中使用语音合成。有两个主要的SAPI版本(SAPI 4和SAPI 5),彼此之间不兼容。
SAPI 5(Microsoft Speech API 5.x)
RHVoice - 免费和开源语音合成器(它支持英语,世界语,格鲁吉亚语,俄语,乌克兰语,吉尔吉斯语和鞑靼语):
RHVoice
UkrVox - 由Yaroslav Kozak(乌克兰利沃夫)创作的乌克兰语音:
UkrVox Igor
Ekho - 免费TTS引擎(它支持广东话,普通话和诏安客家话):
回声(中文)
要获得更好的语音质量,您可以购买Acapela Group,Cepstral或IVONA语音。它们是使用大型语音数据库的新一代TTS引擎,因此语音质量非常出色。
音频剪辑
Balabolka允许将外部音频文件(音频剪辑)的链接插入文档文本。 使用主菜单项“Text | Audio Clip”选择音频文件名。 支持的格式:WAV,MP3,OGG。
拼写检查
Balabolka实施拼写检查引擎Common Speller API(CSAPI)进行拼写检查。 CSAPI旨在用于包含拼写检查的所有Microsoft应用程序
更改 - 使用从“建议”字段中获取的正确单词替换当前单词。
全部更改 - 使用从“建议”字段中获取的正确单词替换说明中所选单词的所有匹配项。
忽略 - 跳过当前单词而不更改它,然后继续下一个拼写错误的单词。
忽略全部 - 跳过描述中当前单词的所有出现而不更改它并继续下一个拼写错误的单词。在整个当前的Balabolka会话期间,这个词将被正确拼写为拼写。
添加 - 将当前单词添加到用户词典。
查找和替换文本
该程序允许搜索当前文档中的文本并将其替换为不同的文本。 非打印字符支持Microsoft Word中的大多数特殊代码:
软件特色
操作简单,没有任何复杂的操作步骤
支持更换语言,例如中文简体、英文等
支持调整文字转换语音朗读时的语速和语调
支持查找文本中某一个字节或字段
支持快捷键操作,例如
Ctrl+L 文本格式
Ctrl+M 查找同行异义词
Ctrl+G 文字替换数字
Ctrl+Alt+F 外语词汇
Ctrl+Alt+D 直接引语
Ctrl+Alt+Ins 插入音频剪辑
Ctrl+Alt+X 插入XML标签
Ctrl+Alt+M 删除所有XMl标签
F4 拼写检查
F5 朗读
F6 暂停
F7 停止
F8 朗读所选文字
F9 朗读剪贴板
......
可更换音频的输出设备
可对文字发音、保存文档、程序启动等功能进行设置
可设置系统托盘、全屏浏览、显示浮动小视窗等
支持自定义设置句子之间的暂停秒数个段落之间的暂停秒数
支持对文件进行分割合并,或批量转换文件
可在文本中插入书签,方便查找
更换规则
词典小组
该应用程序允许使用具有替换规则(“词典”)的特殊文本文件,以改善单词的发音。该文件的每一行包含一个替换规则。规则可以是正则表达式(扩展名为* .rex的文件名)或模板(扩展名为* .dic的文件名)。扩展名为* .bxd的文件结合了其他两种格式的选项。
当用户告诉程序大声朗读文本时,Balabolka会检查字典中文本中哪些单词需要更正发音,并应用字典中的相应替换规则。更改的文本被发送到计算机语音剪贴板,语音朗读文本。
要查看程序使用的词典列表,请选择菜单项“查看|显示|词典面板”或按F11。在主窗口的右侧,将显示文件名列表;它分为两部分:
顶部 - 包含替换列表的文件;
底部 - 带有同形异义词(异名)列表的文件。
不同的计算机语音可以使用不同的替换列表。用户可以从列表中选择必要的文件。
要创建新词典,请右键单击词典面板,然后在上下文菜单中选择“新建”,然后键入新词典的文件名。该文件将在磁盘上创建,其名称将显示在面板的列表中。
如果用户想要修改替换列表,则应从列表中选择文件名,然后单击“编辑”。这将打开一个用于编辑替换列表的窗口。要添加新的替换规则,必须填写“读取此:”和“喜欢这个:”字段,然后单击“添加”。编辑过程完成后,单击“保存”并退出编辑器。
一般规则清单
如果选择列表中的多个文件名,则应用程序会自动将这些词典中的规则合并到存储在计算机内存中的单个列表中。要查看此列表,请在词典面板上单击鼠标右键,然后从弹出菜单中选择“显示列表”。
当来自不同文件的规则被合并到共享列表中时,它发生如下:
来自* .bxd文件的规则一个接一个地添加,因为它们位于词汇表中;文件按字母顺序处理;
从* .rex文件处理规则的相同顺序;
* .dic文件的所有规则都以这样的方式排序:首先是区分大小写的规则,然后是非大小写敏感的规则,然后按模板长度再次排序规则 - 具有最长符号模式的规则放置得更接近顶端。
如果可以将多个规则应用于文本中的相同单词,则列表中的规则顺序非常重要。 Balabolka按顺序执行替换,也就是说,第二个规则将应用于已由列表中的第一个规则修改的文本。在这种情况下,规则的顺序很重要。
将首先应用具有* .rex扩展名的文件中的规则。要检查规则应用于当前文档的结果,请使用主菜单项“选项|发音校正|查看修改后的文本”和“选项|发音校正|替换统计”。
其他工具
要查找影响同一文本的一对规则,请选择菜单项“选项|发音校正|查找规则对”。这允许查找从未使用的规则:另一个规则已经在文本中修改了此表达式。
人们姓名,地名,动物的昵称,组织名称等的发音都需要经常更正。通过主菜单项“选项|发音修正|查找姓名”可以方便地在当前文档中搜索这些单词。在文本“。 Balabolka可以查看三个找到的单词列表:
姓名(总是以当前文件中的大写字母开头的单词);
所有带有大写字母的单词;
在文档文本中找到的所有单词。
当您浏览单词列表时,应用程序将自动朗读单词。如果单词读取不正确,您可以更正发音,为字典添加新规则。找到的名称列表可以按字母顺序排列,也可以按文本中使用单词的频率排序。此外,您可以禁用多次显示文本中出现的单词;这将加快检查当前文档中找到的名称列表。
简介
面板设置的当前状态可以存储为“配置文件”。要创建和编辑配置文件,请使用菜单项“选项|发音校正|配置文件”。
安装方法
1、找到下载完成的压缩包并解压,然后双击“setup.exe”应用程序进入安装步骤。
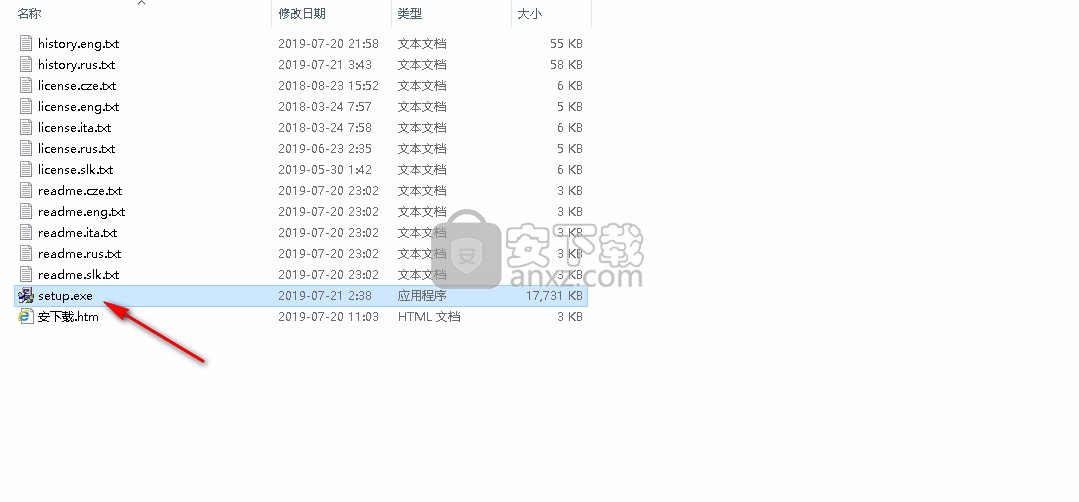
2、选择软件的显示语言,建议选择Chinese(Simplified)简体中文,选择完成后点击【下一步】继续。
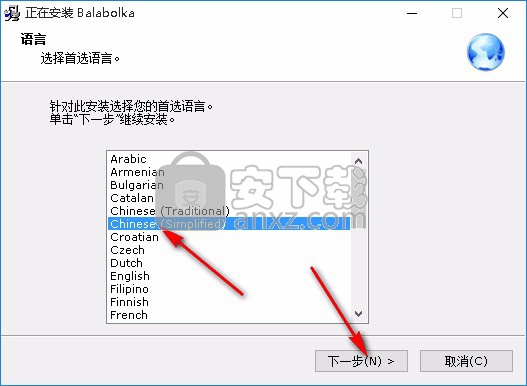
3、安装向导将引导您把此程序安装到您的计算机中,点击【下一步】继续,或单击【取消】退出安装程序。
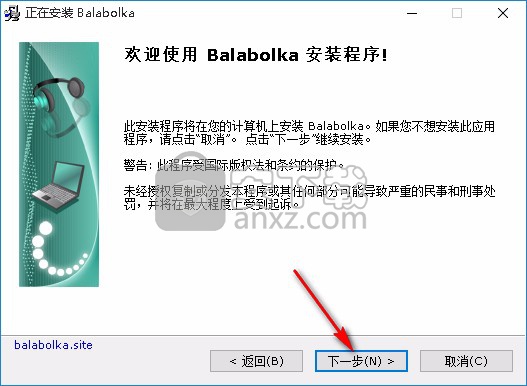
4、如果您想改变程序的存储位置,请单击【浏览】并选择目标文件夹,然后点击【下一步】继续。
5、选附加任务,用户可根据自身的需要来判断是否创建桌面图标和锁定到任务栏选项,选择完成后点击【下一步】继续。
6、等待安装过程,大约五秒钟的时间即可安装完成。
7、安装完成后点击【完成】退出安装向导并默认打开软件。
使用说明
上下文标记定义(SAPI 5)
XML CONTEXT标记指定文本块的规范化。此规范定义了CONTEXT标记的SAPI预定义属性(ID)。这些ID是字符串。 SAPI不对传递给引擎的字符串执行任何参数验证,因此,应用程序可以为引擎指定特定于引擎的规范化ID。特定于引擎的字符串以引擎供应商的名称开头,以避免引擎之间的混淆。
例如:
text
其中一些值的确切实现取决于SAPI 5中使用的引擎。为了强制执行某种规范化,应用程序开发人员可以选择标准化文本,或使用其他SAPI标记或特定于引擎的ID。每个上下文标记可以包含多个字符串。
例如:
12/21/99 11/21/99 10/21/99
将被标准化为“十一月二十九日至一九九九年十一月二十九日至一九九九年十月二十九日二十九日九十九日。”
支持以下预定义上下文类型:
日期
时间
数
卷筒纸
电子邮件
地址
日期
此上下文指定传递给引擎的数字是日期。日期通常具有数字[分隔符]数字[分隔符]数字或数字[分隔符]数字的格式,其中分隔符可以是'。','/'或' - ',并且数字通常在01到12之间数月,01和31天。一年通常是两位或四位数字。
以下是有效的字符串类型:
date_mdy
这将标准化日期,以便第一组数字是月份,第二组是日期,第三组是年份。在年份是两位数的情况下,引擎将其读取为两位数字或四位数字。
例如:
12/21/99
将被标准化为“十二月二十九日九十九”
或“十二月二十一号九十九”
12/21/1999
将被标准化为“十二月二十一日九九九”
date_dmy
这将标准化日期,以便第一组数字是日期,第二组是月份,第三组是年份。在年份是两位数的情况下,引擎将其读取为两位数字。如果年份表示为四位数字,则表示为四位数年份。
例如:
21.12.99
将被标准化为“十二月二十九日九十九”
或“十二月二十一号九十九”
21-12-1999
将被标准化为“十二月二十一日九九九”
date_ymd
这将标准化日期,以便第一组数字是年份,第二组是月份,第三组是日期。在年份是两位数的情况下,引擎将其读取为两位数字。如果年份表示为四位数字,则表示为四位数年份。
例如:
99-12-21
将被标准化为“十二月二十九日九十九”
或“十二月二十一号九十九”
1999.12.21
将被标准化为“十二月二十一日九九九”
date_ym
这将标准化日期,以便第一组数字是年份,第二组是月份。在年份是两位数的情况下,引擎将其读取为两位数字。如果年份表示为四位数字,则表示为四位数年份。
例如:
99-12
将被标准化为“十二月九十九”
或“十二月九十九”
1999.12
将被标准化为“十二月九十九”
date_my
这将使日期标准化,以便第一组数字是月份,第二组是年份。在年份是两位数的情况下,引擎将其读取为两位数字。如果年份表示为四位数字,则表示为四位数年份。
例如:
12/99
将被标准化为“十二月九十九”
或“十二月九十九”
12/1999
将被标准化为“十二月九十九”
date_dm
这将标准化日期,以便第一组数字是日期,第二组是月份。
例如:
21.12
将被标准化为“十二月二十一号”
date_md
这将标准化日期,以便第一组数字是月份,第二组是日期。
例如:
12/21
将被标准化为“十二月二十一号”
date_year
这将标准化日期,以便将该数字读作一年。
例如:
1999
将正常化
XML标签(SAPI 5)
SAPI 5综合标记是插入到文本中的可扩展标记语言(XML)标记的集合,用于修改该文本的语音合成。这些提供音量控制和单词强调等功能的XML标签将插入到文本中。默认情况下,SAPI XML解析器会自动检测XML。在XML结构无效的情况下,程序可能返回说话错误。
每个XML元素都包含一个开始标记和一个结束标记,其中包含不区分大小写的标记名称和这些标记之间的内容。如果元素为空,则它没有内容 ,并且开始标记和结束标记可能是相同的。
所有XML元素必须彼此正确嵌套。
不正确的:
text
正确:
text
由于元素在元素内部打开,因此必须在元素内部关闭它。
使用主菜单项“Text | Insert XML Tag”将标签添加到所选文本。开始标记将插入所选文本的开头,结束标记 - 位于文本末尾。
SAPI文本到语音(TTS)XML标记分为几类。
语音状态控制
直接项目插入
语音环境控制
语音选择
自定义发音
语音状态控制标签
SAPI TTS XML支持五个控制当前语音状态的标签:Volume,Rate,Pitch,Emph和Spell。
体积
音量标签控制语音音量。标记可以为空,在这种情况下,它适用于所有后续文本,或者它可以包含内容,在这种情况下,它仅适用于该内容。
Volume标签有一个必需属性:Level。此属性的值应为0到100之间的整数。超出此范围的值将被截断。
此文本应以50级的音量说出。 此文本应以音量级别100说出。
以下所有文本都应以80级的音量说出。
一百表示语音的默认音量。较低的值表示此默认值的百分比。也就是说,50对应于全量的50%。
率
Rate标签控制语音的速率。标记可以为空,在这种情况下,它适用于所有后续文本,或者它可以包含内容,在这种情况下,它仅适用于该内容。
Rate标签有两个属性,Speed和AbsSpeed,其中一个必须存在。这两个属性的值应该是负十和十之间的整数。超出此范围的值可能会被引擎截断(但不会被SAPI截断)。 AbsSpeed属性控制语音的绝对速率,因此值10总是对应于值10,值5总是对应于值5。
本文应以第五速率发言。 此文本应以负5的速率发言。
以下所有文字都应以十分之一的速度发言。
“速度”属性控制语音的相对速率。通过将每个Speed添加到当前绝对值来找到绝对值。
此文本应以第五速率发言。 此文本应以零速率说出。
零表示语音的默认速率,正值更快,负值更慢。
沥青
Pitch标签控制语音的音高。标记可以为空,在这种情况下,它适用于所有后续文本,或者它可以包含内容,在这种情况下,它仅适用于该内容。
Pitch标签有两个属性,Middle和AbsMiddle,其中一个必须存在。这两个属性的值应该是负十和十之间的整数。超出此范围的值可能会被引擎截断(但不会被SAPI截断)。
AbsMiddle属性控制语音的绝对音高,因此值10总是对应于值10,值5总是对应于值5。
本文应以第五档说出。 这个文本应该以负数五来说。
以下所有文字都应以第十音说出。
Middle属性控制语音的相对音高。通过将每个Middle添加到当前绝对值来找到绝对值。
本文应以第五音说出。 此文本应以零间距说出。
零表示语音的默认中间音调,正值较高而负值较低。
EMPH
Emph标签指示语音强调文字的一个单词或一部分。 Emph标签不能为空。应强调以下几个字。
boo !
强调方法可能因语音而异。
常见问题
问题我收到错误消息“OLE错误80045042”。那是什么意思?
回答此错误表示:“由于语法错误,XML解析器失败。”您必须验证文本中XML标记的语法。或者,文本的某些部分看起来像是XML标记的开头,而且令SAPI感到困惑。如果您不想使用XML标记,请从文本中删除符号“<”和“>”(或者用“小于”和“大于”字样替换它们)。
问题我在哪里可以获得SAPI 4?
解答要使用SAPI 4语音,请下载并安装可再发行的Microsoft Speech API文件(824 KB)。此外,您可以下载并安装Microsoft语音控制面板(840 KB);语音控制面板将在控制面板上添加一个图标,使您能够列出系统上安装的兼容的文本到语音引擎,并自定义其设置供您使用。
问题我在哪里可以获得SAPI 5?
回答Windows XP(及更高版本)附带SAPI 5。
问题如何知道计算机上安装了哪些文字转语音?
解答您可以按照控制面板 - >语音 - >语音属性 - >文本到语音 - >语音选择查看计算机上可用的所有语音。
问题如何进行Balabolka的静音安装?
解答要在没有对话框的静默模式下安装Balabolka,您可以使用静默安装。使用-silent命令行开关可以进行静默安装。
问题我打开一个DjVu文件,但程序没有显示任何文本。怎么了?
答案DjVu格式旨在存储扫描的文档。 DjVu文件包含书籍,杂志等页面的图像。此外,DjVu可以包含OCR文本层。
Balabolka只能从DjVu的文本层中提取数据。如果此类图层不可用,获取文本的唯一方法是使用文本识别系统(例如,FineReader)。
问题我的电脑包含两张声卡。如何为文本到语音播放选择音频设备?
解答您可以在Windows的“控制面板”中选择“语音”,然后单击“语音属性”对话框中的“音频输出”按钮。此外,Balabolka包含主菜单项“选项|音频输出”。
问题我的电脑正在运行64位版本的Windows。我已经为Microsoft Speech Platform和英语语音安装了64位Runtime软件包。但可用声音列表仍然是空的。哪里有问题?
回答Balabolka是32位应用程序。您还需要为Microsoft Speech Platform安装32位Runtime软件包。
问题每当文本包含不间断空格(ALT + 0160)时,语音就会显示“空格”。如何解决这个问题?
解答程序可以在阅读过程中自动用常规空格替换不间断空格。选择主菜单项“选项|设置”,在“设置”窗口(“阅读”选项卡)中选中“读取时忽略字符”框。将不间断空格添加到可忽略符号列表中:按ALT并在数字键盘上键入“0160”。
问题如何删除段落开头的破折号?
解答您应该使用主菜单项“编辑|替换”。在“查找内容”框中键入^ p-,在“替换为”框中键入^ p。您可以在此处找到有关特殊代码的更多信息。
问题什么是Google文字转语音?
回答在Google翻译中,您可以找到将文本转换为语音的“收听”按钮。按下此按钮后,浏览器开始下载MP3文件。该服务支持转换为不超过100个符号的语音文本。 Balabolka允许在小部件上划分大文本,为每个部件创建音频文件并将它们合并在一起(支持WAV,MP3和OGG格式)。
问题我使用声音eSpeak将字幕转换为音频文件。但结果音频文件包含没有暂停的语音。哪里有问题?
回答我强烈建议不要使用eSpeak进行字幕转换。这些声音不支持XML标签“沉默”;同样的问题出现在其他一些声音的旧版本中。建议使用最新版本的商业软件(Cepstral,CereProc,IVONA等)。
问题我不满意,Balabolka如何从PDF文件中提取文本。我可以使用其他方式处理PDF吗?
回答从PDF文件中提取文本的过程非常复杂,因为PDF文件不包含纯文本。您可以使用外部命令行实用程序进行文本提取:例如,Xpdf项目中的程序pdftotext.exe。将pdftotext.exe复制到Balabolka文件夹中的子文件夹“utils”,选择主菜单项“Options | Text Import”,选项卡“Custom Text Import”,然后单击Add按钮。定义使用pdftotext.exe的命令:
%BFolder% utils pdftotext.exe -q -nopgbrk -enc UTF-8%输入%%输出%
定义转换器的名称(例如,“Xpdf Converter”),文件扩展名(“PDF”)和输出编码(“UTF-8”)。激活选项Use而不是default extrac后
更新日志
v2.15.0.793
[+]添加了选项“显示整个句子”的编辑同形异义词(标签文本“找到”)。
[-]固定Naver语音的使用。
[-]固定使用微软的翻译。
v2.15.0.752
*为全局热键“朗读剪贴板”添加了“按一次开始读取然后暂停一次”选项。
*添加了主菜单项“删除”。
*修复了小错误。
*更新了保加利亚语和土耳其语的资源(感谢Kostadin Kolev和arDoan)。
相关下载
- 查看详情 Balabolka(语音阅读器) v2.15.0.805 22.71 MB简体中文21-11-18 14:55
人气软件
-

adobe reader 10.0中文官方版 53.9 MB
/简体中文 -

CAJViewer(caj阅读器) 263.43 MB
/简体中文 -

Adobe Acrobat 7.0 pro中文专业 210 MB
/简体中文 -

Adobe Acrobat XI Pro 单文件全能版 33.00 MB
/简体中文 -

福昕PDF阅读器 Foxit Reader 67.56 MB
/简体中文 -

adobe reader xi 官方简体中文版 53.9 MB
/简体中文 -

超星阅览器 11.95 MB
/简体中文 -

neat reader 74.2 MB
/简体中文 -

adobe acrobat pro dc 2017 758 MB
/简体中文 -

adobe acrobat reader dc 2021简体中文版 327.0 MB
/简体中文
 极速pdf阅读器 3.0.0.3030
极速pdf阅读器 3.0.0.3030  悦书pdf阅读器 4.3.1.0
悦书pdf阅读器 4.3.1.0  Effie写作软件 v3.8.3
Effie写作软件 v3.8.3  ReadBook阅读器 v1.63 (内置激活码)
ReadBook阅读器 v1.63 (内置激活码) 












